If you have been reading this blog, you have probably noticed how all the debugging and analysis of applications have been on Windows executables, and although I did create my own Linux distribution, Dapper Linux, I haven’t written much about debugging on Linux.
Time to change that. Today, we are going to look into how debugging Linux kernel crash dumps works on Ubuntu 18.10 Cosmic Cuttlefish. Fire up a virtual machine, and follow along.
We will cover how to install and configure crash and kdump, a little on how each tool works, and finding the root cause of a basic panic.
Let’s get started.
kdump
kdump is a tool which captures crash dumps from the memory of a running crashed system. The architecture is slightly interesting, since when the production kernel crashes, another, separate kernel is booted via kexec, into a memory space reserved by the production kernel. The freshly booted separate kernel, also known as the crash kernel, then captures the state of the crashed system, and writes it to disk.
This all works because of kexec. kexec is a fastboot tool implemented in the kernel. It allows other kernels to be booted from an already running kernel, skipping the need to go through standard BIOS routines. This, coupled with the fact that the crash kernel is loaded into reserved space allocated by the production kernel, means that memory is intact and is not overwritten by a reboot. This is how reliability and integrity of crash dumps are assured.
Once the crash dump is written to disk, or even sent over the network to a remote host, the system reboots so uptime can be restored. The crash dump can then be analysed later on.
Configuring kdump
Kernel Configuration
If we read the kdump Documentation, kdump requires some kernel features to be configured and compiled into the kernel.
They are:
- CONFIG_KEXEC=y
- CONFIG_CRASH_DUMP=y
- CONFIG_PROC_VMCORE=y
- CONFIG_DEBUG_INFO=y
- CONFIG_MAGIC_SYSRQ=y
- CONFIG_RELOCATABLE=y
- CONFIG_PHYSICAL_START=0x1000000
CONFIG_KEXEC enables the syscall required for kexec to function, and is necessary for being able to boot into the crash kernel.
CONFIG_CRASH_DUMP and CONFIG_PROC_VMCORE enables the crashed kernel to be dumped from memory, and exported to a ELF file.
CONFIG_DEBUG_INFO builds the kernel with debugging symbols, and produces a vmlinux file which can be used for analysis of crash dumps. The production kernel runs a kernel stripped of debugging symbols for performance, so it is very important to match packages of production kernels and debug kernels.
CONFIG_MAGIC_SYSRQ is necessary to be able to use SYSRQ features, such as flushing buffers on kernel panic, and to be able to trigger crashes manually.
CONFIG_RELOCATABLE is set since our kernel is relocatable in memory, so we must also set CONFIG_PHYSICAL_START as the deterministic address in which we can place the crash kernel in memory. Now, 0x1000000 is at 16mb in physical memory, and is the default set in Cosmic Cuttlefish’s kernel.
The nice thing is, all of these features are enabled by default on Ubuntu production kernels, so we don’t need to compile our own kernel today. You can verify that these features are enabled by looking at the config files in /boot:
$ grep -Rin "CONFIG_CRASH_DUMP" /boot/config-4.18.0-15-generic
695:CONFIG_CRASH_DUMP=y
Installing Packages
We can install all the required kdump packages with the command: sudo apt install linux-crashdump. This will install crash, kdump-tools, kexec-tools, makedumpfile and itself.
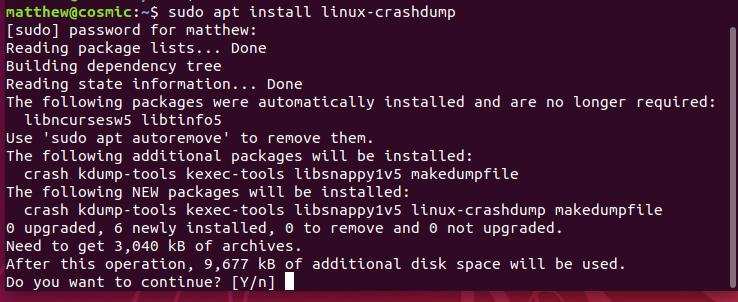
Once the packages are installed, we get asked the following:
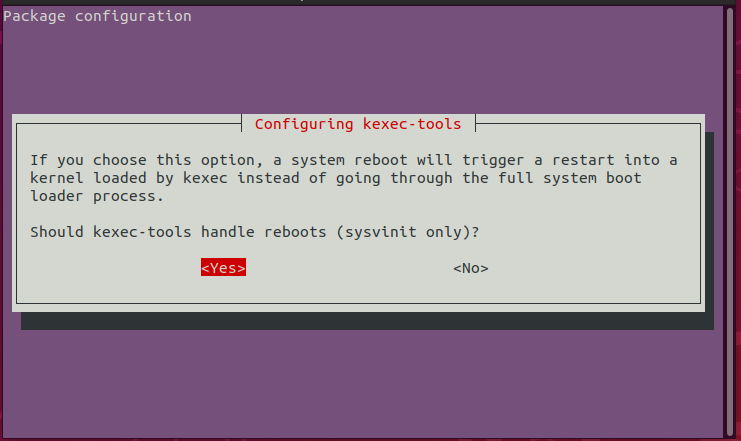
Should kexec-tools handle reboots (sysvinit only)?
Well, we do want kexec-tools to hook all reboots, so it starts the crash kernel when the system is forcefully rebooted. I’m not entirely sure about why the question says it applies to sysvinit only, since Cosmic Cuttlefish uses systemd as its init system, but I am going to say yes anyway.
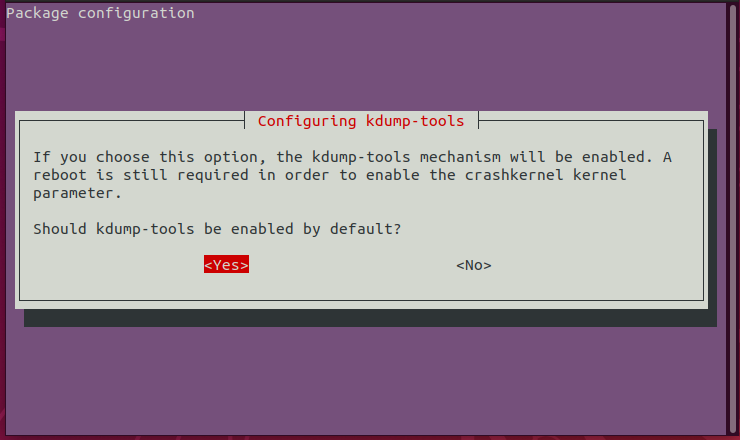
Should kdump-tools be enabled by default?
Well, we are here to learn how to use kdump, so yes, we do want kdump-tools to be enabled by default.
We should probably make sure we have all the necessary kernel packages around as well, such as headers and tools, so run:
$ sudo apt install linux-image-generic linux-headers-generic linux-tools-generic
Setting up kdump-tools
We need to tell the kernel where the crash kernel will be loaded in memory, and how much space it has. This happens by appending a crashkernel=... to the kernel command line. This has been done for us when we installed linux-crashdump, and we need to reboot the system so that the changes actually take effect. So go ahead and restart.
After restarting, we can see run kdump-config show, to see that all is well:
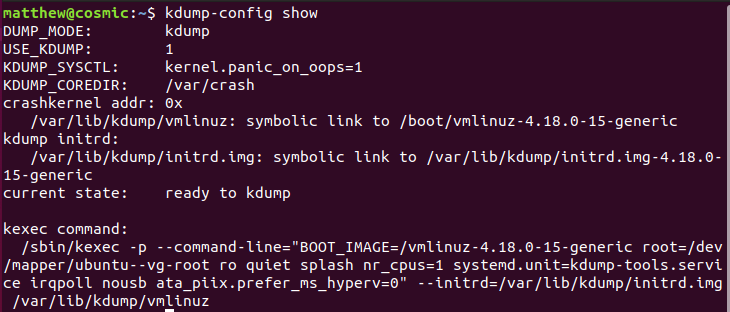
A few interesting things to note:
- Core dumps will be stored in
/var/crash - The crash kernel vmlinuz is located at
/var/lib/kdump/vmlinuz - The crash kernel initial filesystem is located at
/var/lib/kdump/initrd.img
To see the updated kernel command line, we can run cat /proc/cmdline:

We see that if the system has more than 512Mb of ram, 192Mb is allocated for the crash kernel.
Crashing the System
Time for the main event, testing out kdump. We will do this via SYSRQ, and its ability to force a crash and then a reboot.
We can check that it is enabled by looking at /proc/sys/kernel/sysrq. 0 is disabled, and 1 is all features enabled.
$ cat /proc/sys/kernel/sysrq
176
What a strange number. We will have to look at /etc/sysctl.d/10-magic-sysrq.conf to see what 176 means.
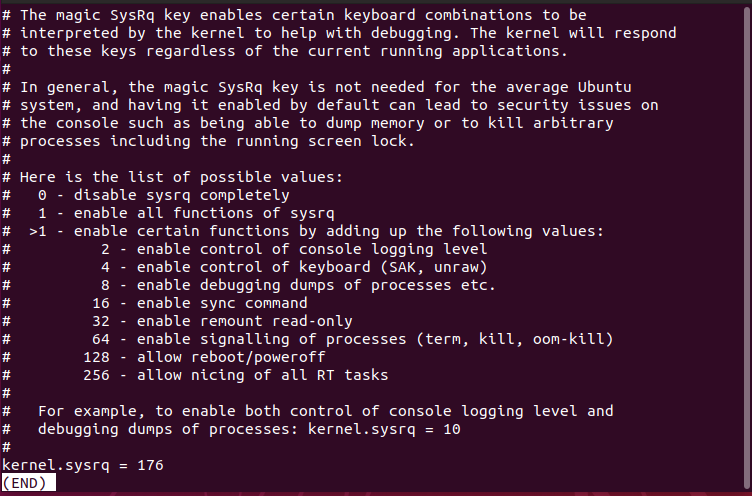
176 can be broken down into 128, 32 and 16. This means that SYSRQ can reboot the system, remount disks as read only and sync buffers to disk.
To make sure this works, we will enable all features by setting the value to 1:
$ sudo sysctl -w kernel.sysrq=1
Right. We can trigger a system crash by passing the ‘c’ character to /proc/sysrq-trigger. This has to be done as root:
$ sudo -s
# echo c > /proc/sysrq-trigger
The system will now crash, and a reboot will occur. It looks pretty strange when seeing it on a graphical session, as plymouth gets started during boot of the crash kernel, and I am asked for my LUKS key, since I was testing LVM + LUKS on this particular VM.
After a few seconds the system will reboot for real this time, and the production kernel boots normally.
Debugging the Panic with crash
Okay, so our system just crashed. Time to figure out what went wrong and to find where in the source code the problem occurs.
To be able to start crash, we need a kernel with debugging symbols built in. Now, this kernel has to exactly match the production kernel that we crashed, and cannot be compressed. For Ubuntu systems, we are looking for the kernel ddeb.
We can add the ddeb repository to our system with:
$ sudo tee /etc/apt/sources.list.d/ddebs.list << EOF
deb http://ddebs.ubuntu.com/ $(lsb_release -cs) main restricted universe multiverse
deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-security main restricted universe multiverse
deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-updates main restricted universe multiverse
deb http://ddebs.ubuntu.com/ $(lsb_release -cs)-proposed main restricted universe multiverse
EOF
We can then import the GPG key for the repo, refresh package lists and install the vmlinux package with:
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys C8CAB6595FDFF622
$ sudo apt update
$ sudo apt install linux-image-$(uname -r)-dbgsym
Watch out though, the download is 830MB, and takes a lot of time, since it is not mirrored in New Zealand.
Starting crash
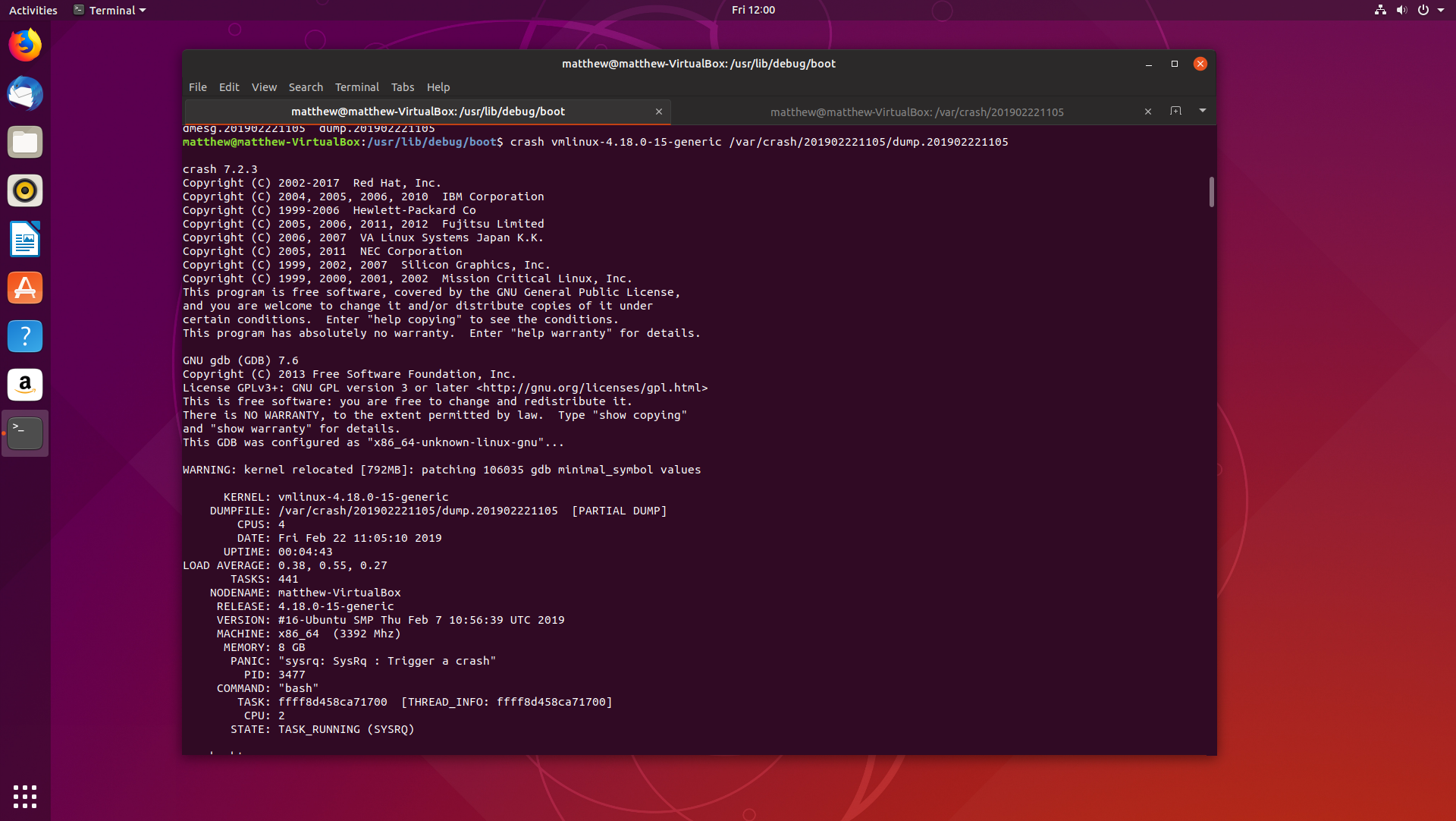
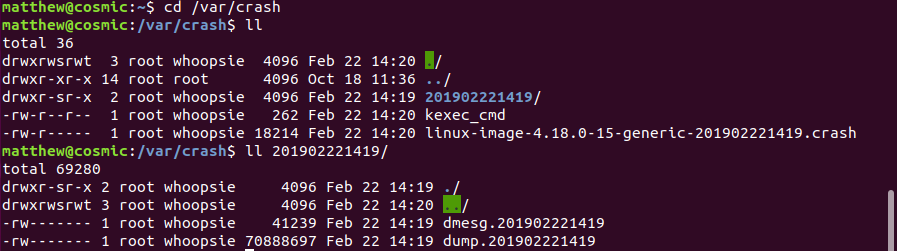
The crash dump is stored in /var/crash, in a directory named with the timestamp of when the crash took place:
The debug kernel is located in /usr/lib/debug/boot/:

We can start crash with the syntax crash <vmlinux> <dumpfile>
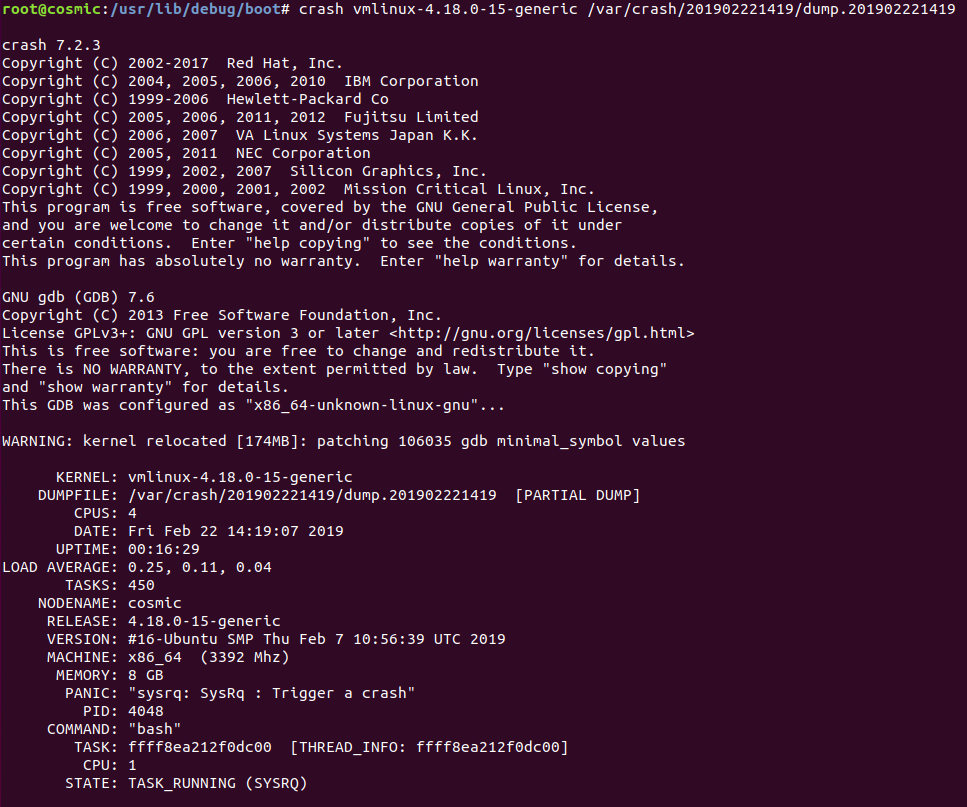
When we first run crash, we get a list of basic system configuration, such as the kernel version, system uptime, the date, number of tasks, the hostname, what process was running, and the PID of the process.
We can get a view of the processes the system was running with the ps command:
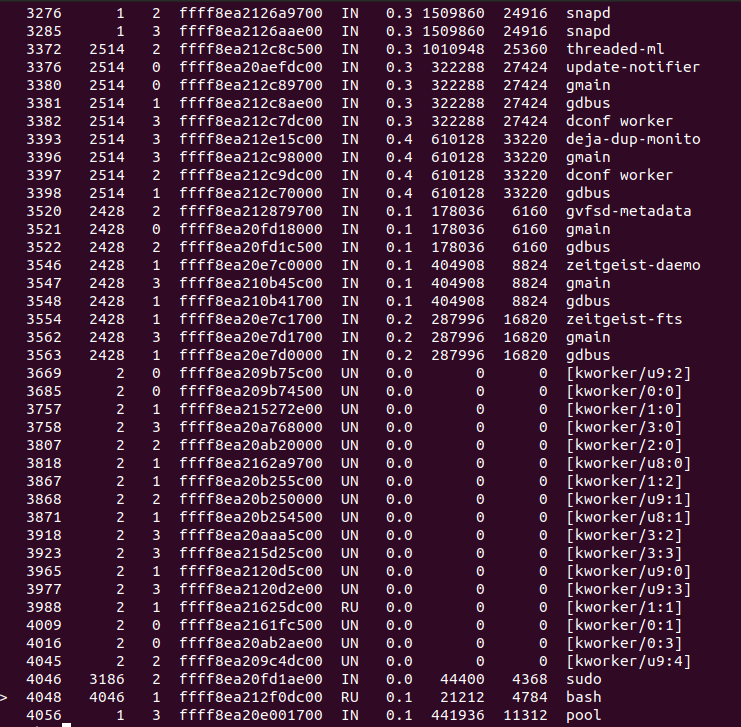
Note that the crashed process is shown with ‘>’.
The log command brings up the contents of dmesg, for that particular session.
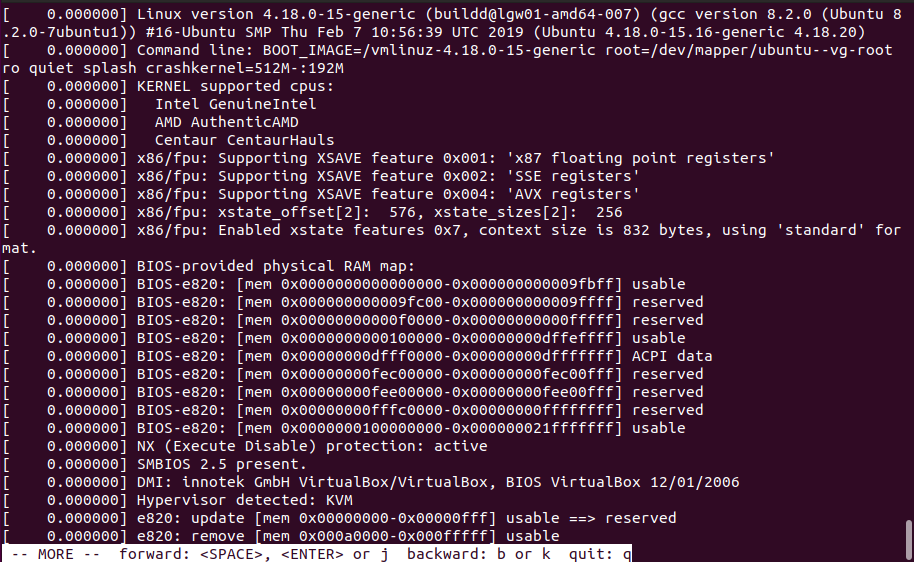
The most interesting part is the bottom, where Oops message is printed to the log:
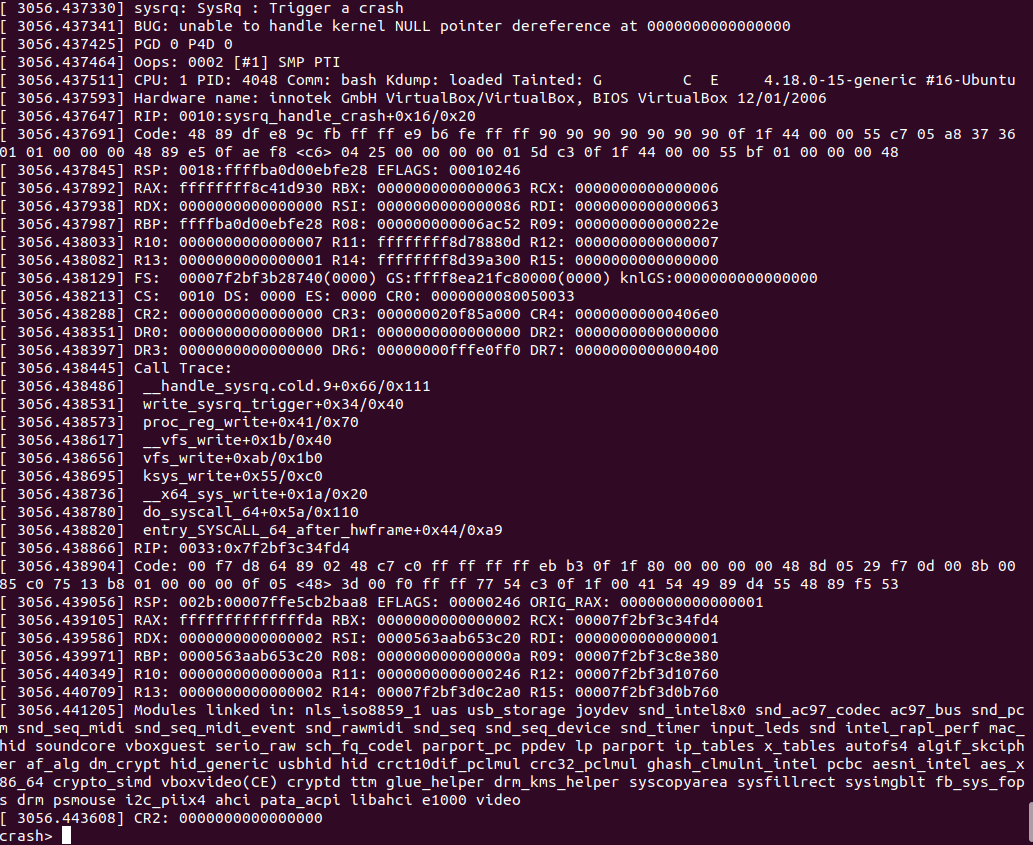
For this particular crash, the Oops message prints out more than enough debugging information to solve this particular problem. But for more complex bugs, the bt command is interesting.
bt normally shows the backtrace of the task which caused the system crash, but you can select other tasks and fetch their backtraces as well.
The output for bt is:
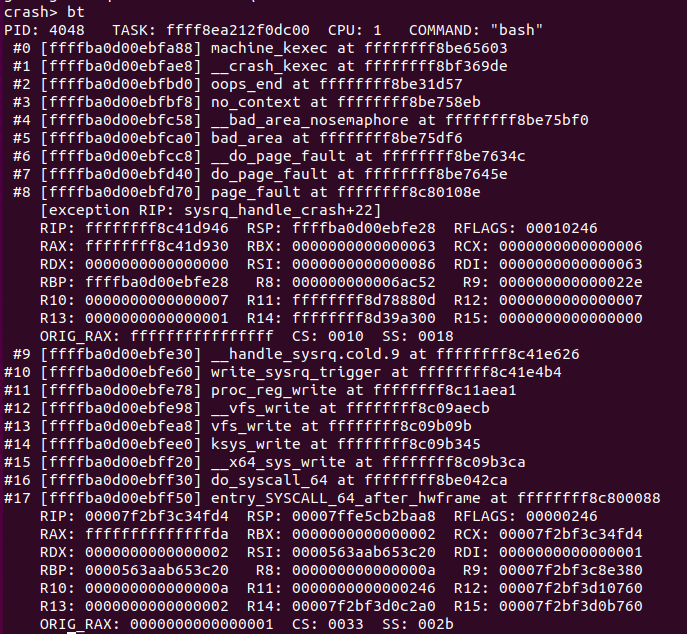
Let’s try and find the root cause of this crash. bt shows us that a write was taking place, due to all the write releated syscall functions and vfs write calls.
bt shows us that the instruction pointer that caused the initial exception was inside the function sysrq_handle_crash, at offset +22.
We can get a better view of sysrq_handle_crash by disassembling the function with the dis command:

At offset +22, we see a call to mov BYTE PTR ds:0x0,0x1, which tried to move 1 into the address 0x0. Now, you can’t write to a null pointer, since reading or writing to address 0x0 is forbidden.
We see that this causes a page fault, which eventually calls bad_area which then goes onto triggering a crash. From there, we can see __crash_kexec and machine_kexec take over after oops_end, and the system boots into the crash kernel to capture the dump.
To look a little more closely at the root cause of the problem, we can fetch a copy of the kernel source code and review it:
$ git clone --depth 1 git://kernel.ubuntu.com/ubuntu/ubuntu-cosmic.git
Cloning into 'ubuntu-cosmic'...
$ cd ubuntu-cosmic/
$ grep -Rin "sysrq_handle_crash" .
./drivers/tty/sysrq.c:135:static void sysrq_handle_crash(int key)
./drivers/tty/sysrq.c:150: .handler = sysrq_handle_crash,
Opening up drivers/tty/sysrq.c at line 135:
static void sysrq_handle_crash(int key)
{
char *killer = NULL;
/* we need to release the RCU read lock here,
* otherwise we get an annoying
* 'BUG: sleeping function called from invalid context'
* complaint from the kernel before the panic.
*/
rcu_read_unlock();
panic_on_oops = 1; /* force panic */
wmb();
*killer = 1;
}
killer is a NULL pointer, and 1 is being written to a de-referenced killer. We have found the root cause, and it agrees with the disassembly.
Resources Used
When I was first learning how to use kdump and crash I read the following:
- Kernel Crash Dump - Ubuntu Documentation
- CrashdumpRecipe - Ubuntu Wiki
- Dumping a Linux Kernel
- Collecting and analyzing Linux kernel crashes - Kdump - Dedoimedo
- Collecting and analyzing Linux kernel crashes - crash - Dedoimedo
This writeup is more or less a collection of all above resources into one easy to read blog post.
I hope you enjoyed the read.
Matthew Ruffell