-
Reflecting on the Azure DNS Outage - A Post Incident Analysis 09 Dec 2022
During my work as a Sustaining Engineer at Canonical, occasionally I get tasked with analysing and fixing high profile regressions that turn into world ending emergencies. I think I have worked on four or five of these cases now, and behind each and every one there is a story to tell, and lessons to be learned.
Today, we will dive into the intricate and complex series of events that caused the worldwide Azure AKS Cloud outage, for systems running Ubuntu 18.04 LTS, which I had the responsibility and leadership to resolve.
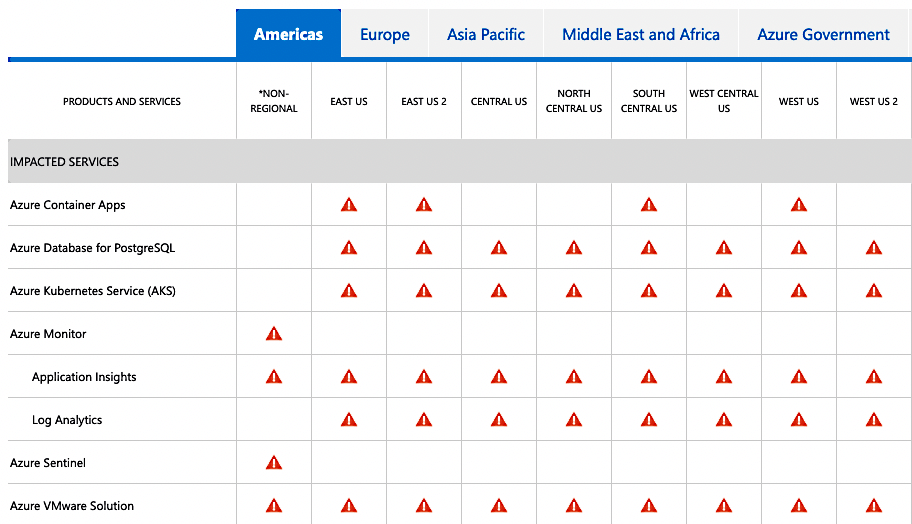
So, go brew a cup of coffee or whip up a hot chocolate, and let’s recount the events that happened four months ago, and how we worked to resolve them without causing another world ending event to occur.
-
Investigating Missing Stack Canaries and Fortify Source on Binaries 10 Jun 2022
Not too long ago, I worked on a fairly interesting case where a user claimed that many of the binaries on their system were missing Stack Canaries provided through
-fstack-protector-strongand additionally, many were missing Fortify Source being enabled through-D_FORTIFY_SOURCE=2.This is most unusual, since these compiler flags, along with many others, are enabled by default for all packages in the Ubuntu archive.
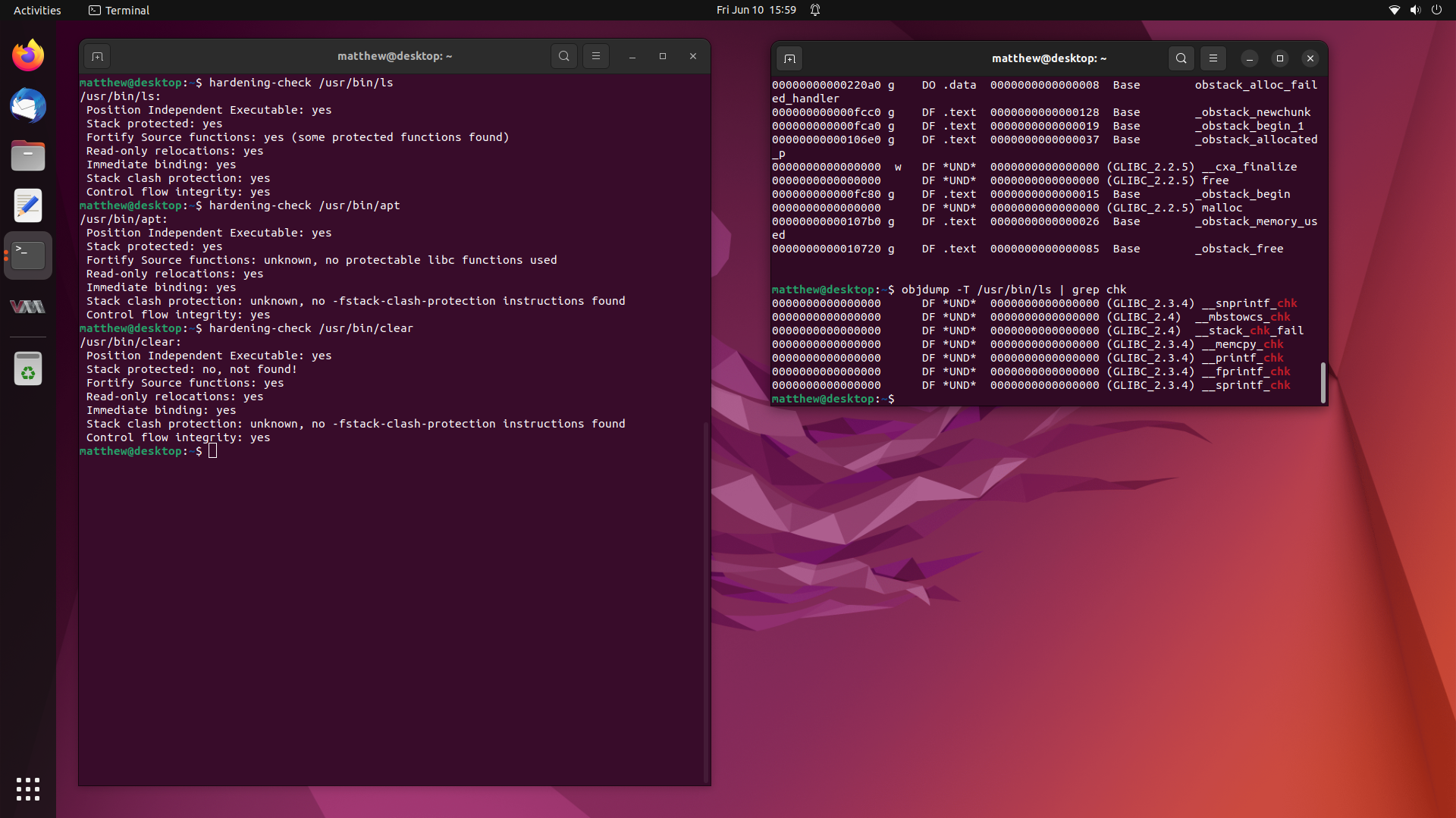
So in this writeup, we are going to investigate this user’s claims, and try get to the bottom of the mystery of the missing compiler hardening options in binaries from the Ubuntu archive. Stay tuned.
-
Learning How to Write Reactive Charms by Porting our Minetest Charm 07 Sep 2021
It has been a really long time since my last blog post, so let’s fix that by writing a followup post to my popular article on learning to write Juju Charms, where we wrote a simple Charm to deploy a production ready Minetest server, complete with postgresql integration through Juju relations.
Today, we are going to go a step further and delve into Reactive Charms, where we can define and maintain state through flags. Flags let us have a memory of events that have happened in the past, and only run certain functions to “react” to changes in those flags.
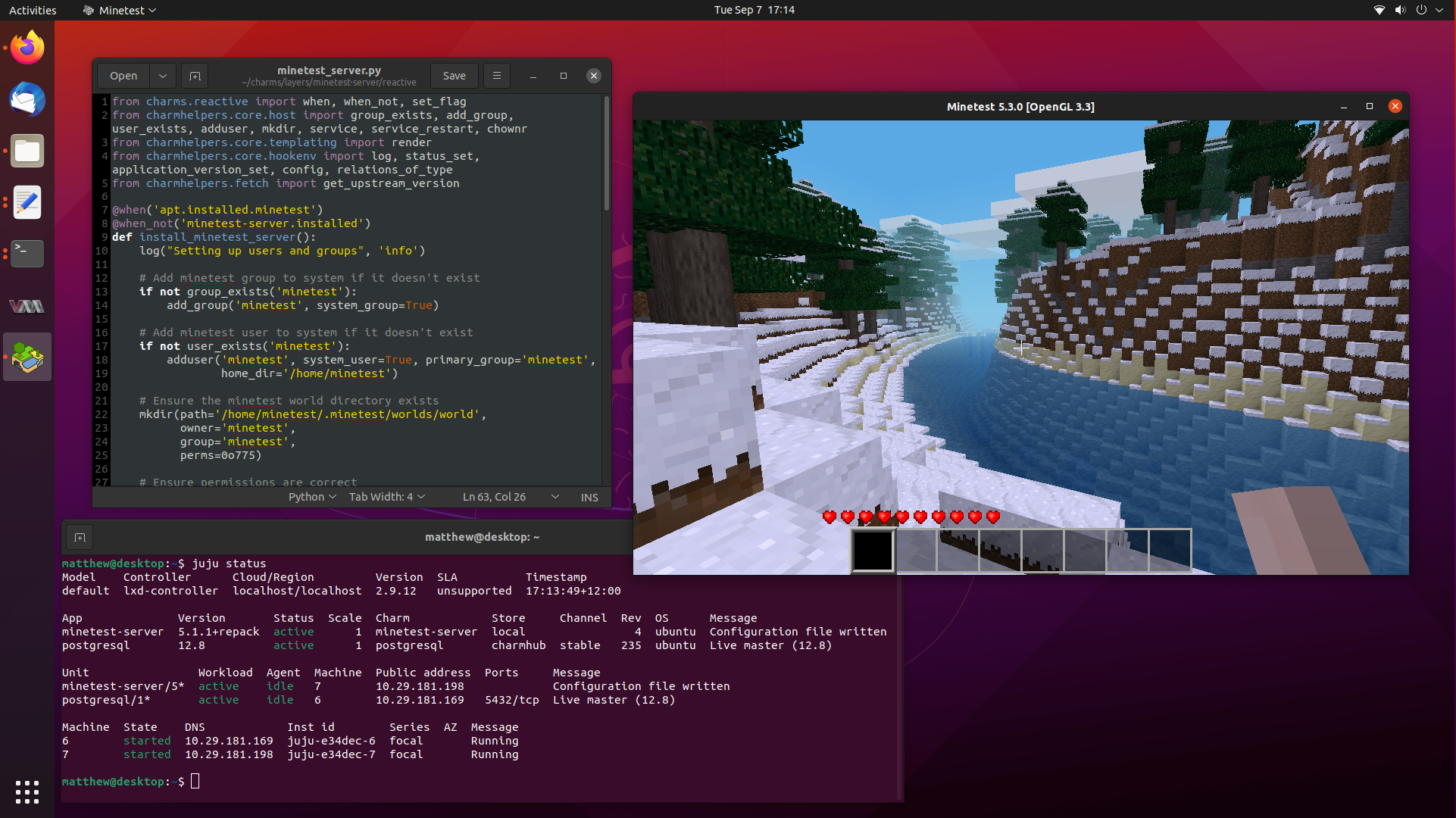
Reactive Charms are primarily written in Python, and there are a lot of different submodules that exist to help you develop your Charm. So buckle up, because we are going to take our little Minetest Charm to the next level.
-
Getting DMESG_RESTRICT Enabled in Ubuntu 20.10 Groovy Gorilla 24 Oct 2020
You might have noticed a small change when running the
dmesgcommand in Ubuntu 20.10 Groovy Gorilla, since it now errors out with:dmesg: read kernel buffer failed: Operation not permittedDon’t worry, it still works, it has just become a privileged operation, and it works fine with
sudo dmesg. But why the change?Well, I happen to be the one who proposed for this change to be made, and followed up on getting the configuration changes made. This blog post will describe how it slightly improves the security of Ubuntu, and the journey to getting the changes landed in a release.
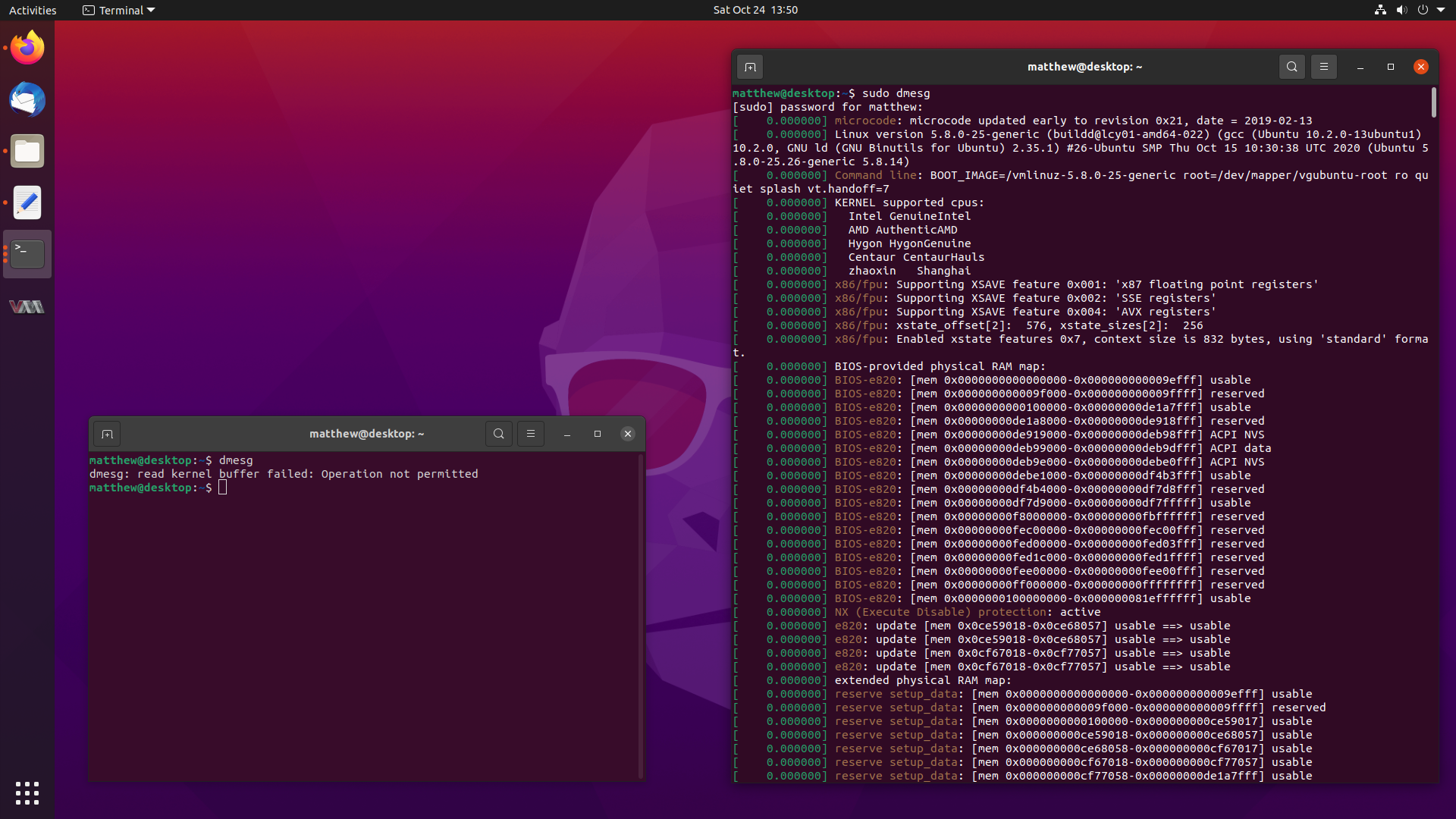
So stay tuned, and let’s dive into
dmesg. -
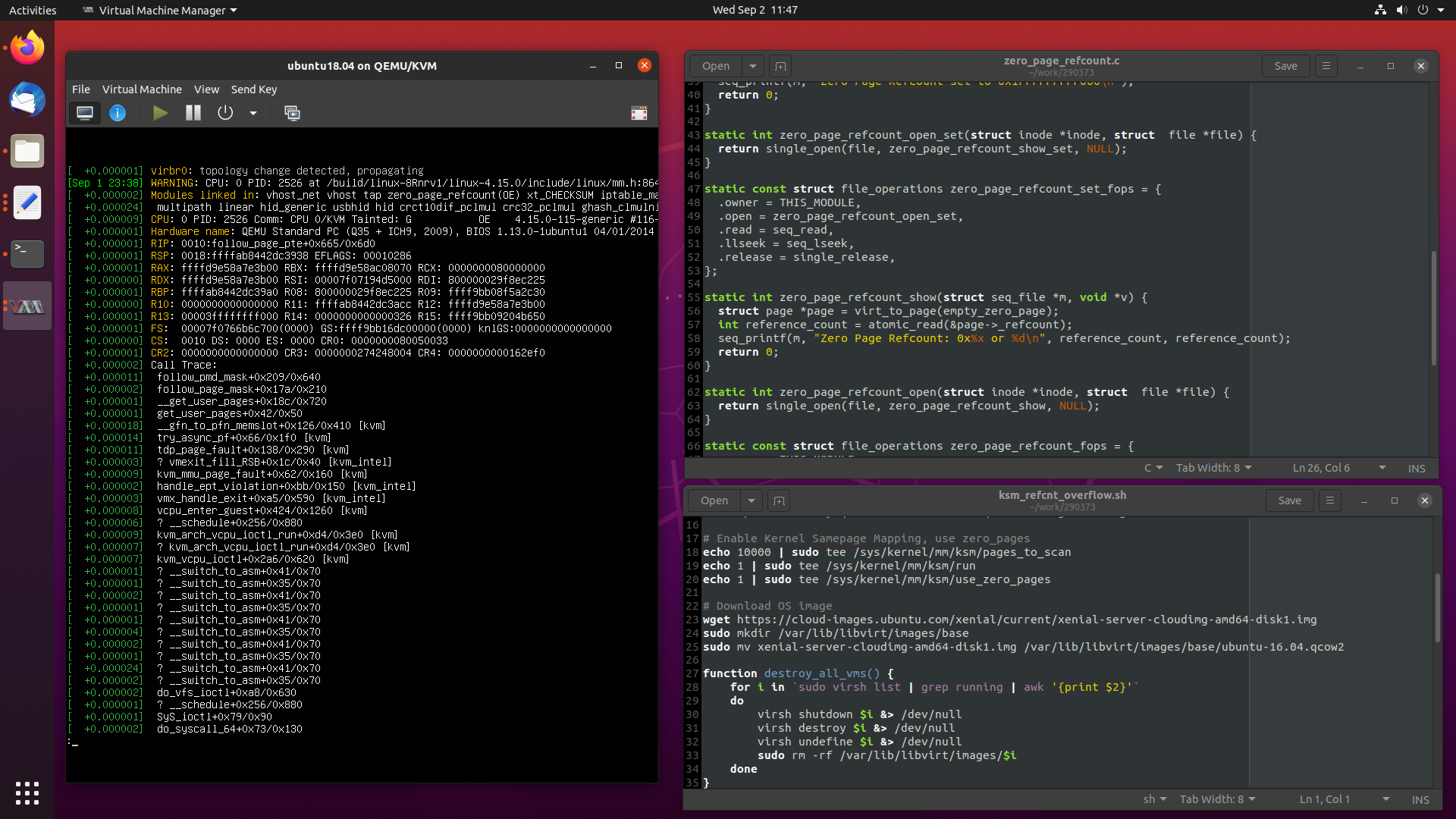
Debugging a Zero Page Reference Counter Overflow on the Ubuntu 4.15 Kernel 02 Sep 2020
Recently I worked a particularly interesting case where an OpenStack compute node had all of its virtual machines pause at the same time, which I attributed to a reference counter overflowing in the kernel’s
zero_page.Today, we are going to take a in-depth look at the problem at hand, and see how I debugged and fixed the issue, from beginning to completion.
Let’s get started.
-
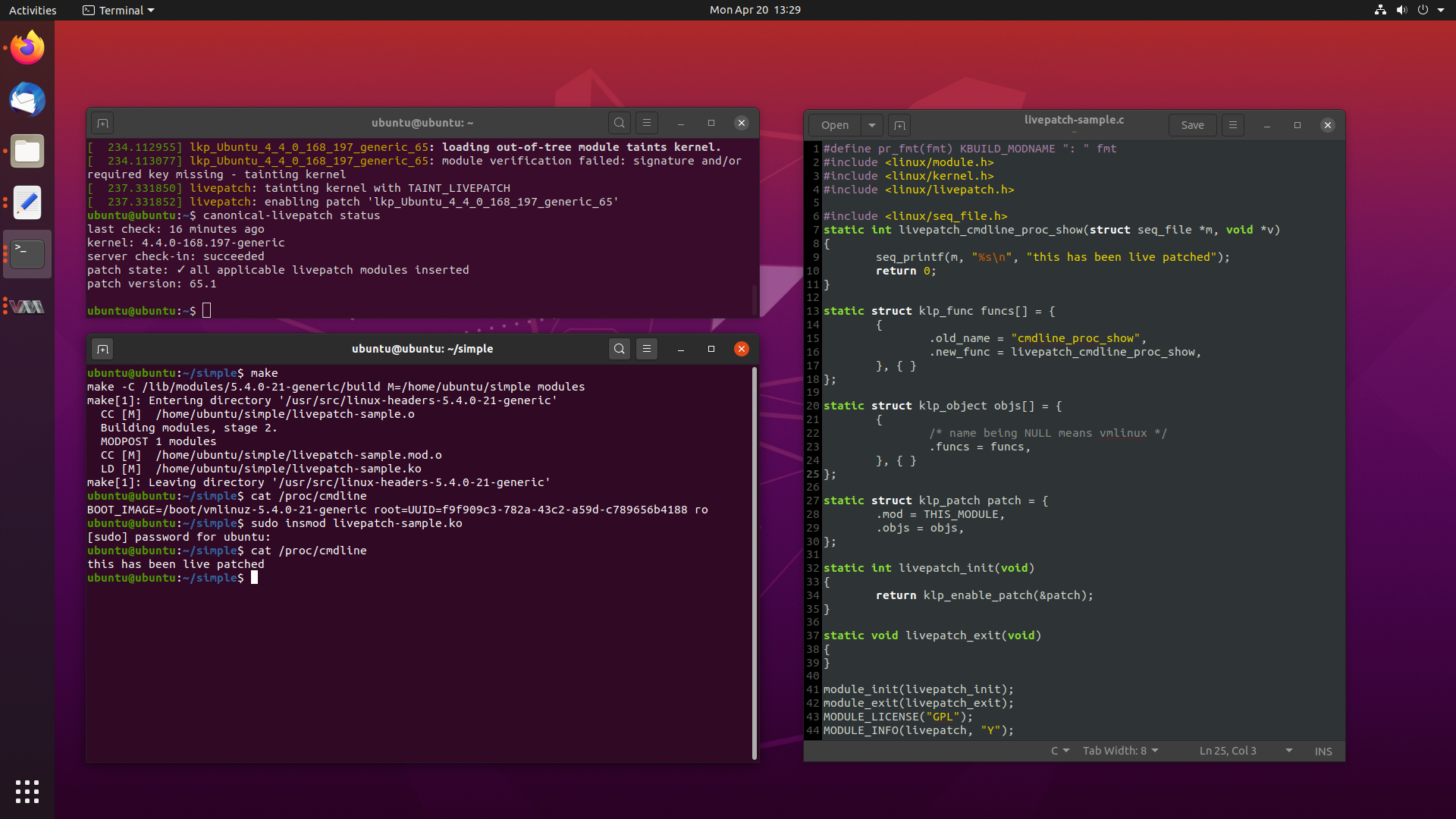
Everything You Wanted to Know About Kernel Livepatch in Ubuntu 20 Apr 2020
One of the more recent killer features implemented by most major Linux distros these days is the ability to patch the kernel while it is running, without the need for a reboot.
While this may sound like sorcery for some, this is a very real feature, called Livepatch. Livepatch uses ftrace in new and interesting ways, by patching in calls at the beginning of existing functions to new patched functions, delivered as kernel modules.
This lets you update and fix bugs on the fly, although its use is typically reserved for security critical fixes only.
The whole concept is extremely interesting, so today we will look into what Livepatch is, how it is implemented across several distros, we will write some Livepatches of our own, and look at how Livepatch works in Ubuntu for end users.
-
Deploying an OpenStack Cluster in Ubuntu 19.10 13 Feb 2020
The next article in my series of learning about cloud computing is tackling one of the larger and more widely used cloud software packages - OpenStack.
OpenStack is a service which lets you provision and manage virtual machines across a pool of hardware which may have differing specifications and vendors.
Today, we will be deploying a small five node OpenStack cluster in Ubuntu 19.10 Eoan Ermine, so follow along, and let’s get this cluster running.
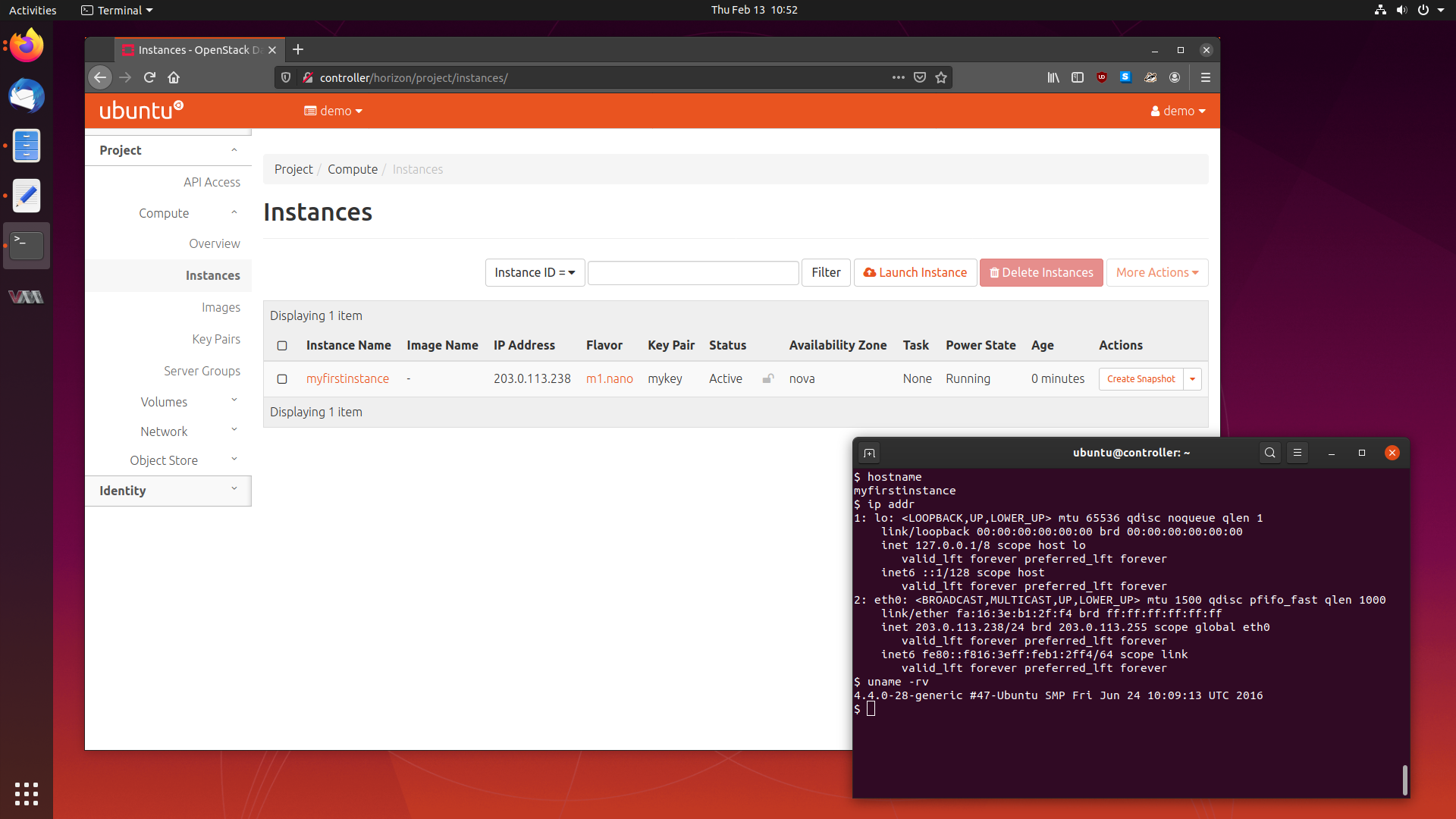
We will cover what OpenStack is, the services it is comprised of, how to deploy it, and using our cluster to provision some virtual machines.
Let’s get started.
-
Analysis of an Out Of Memory Kernel Bug in the Ubuntu 4.15 Kernel 13 Dec 2019
As mentioned previously, I will write about particularly interesting cases I have worked from start to completion from time to time on this blog.
This is another of those cases. Today, we are going to look at a case where creating a seemingly innocent RAID array triggers a kernel bug which causes the system to allocate all of its memory and subsequently crash.
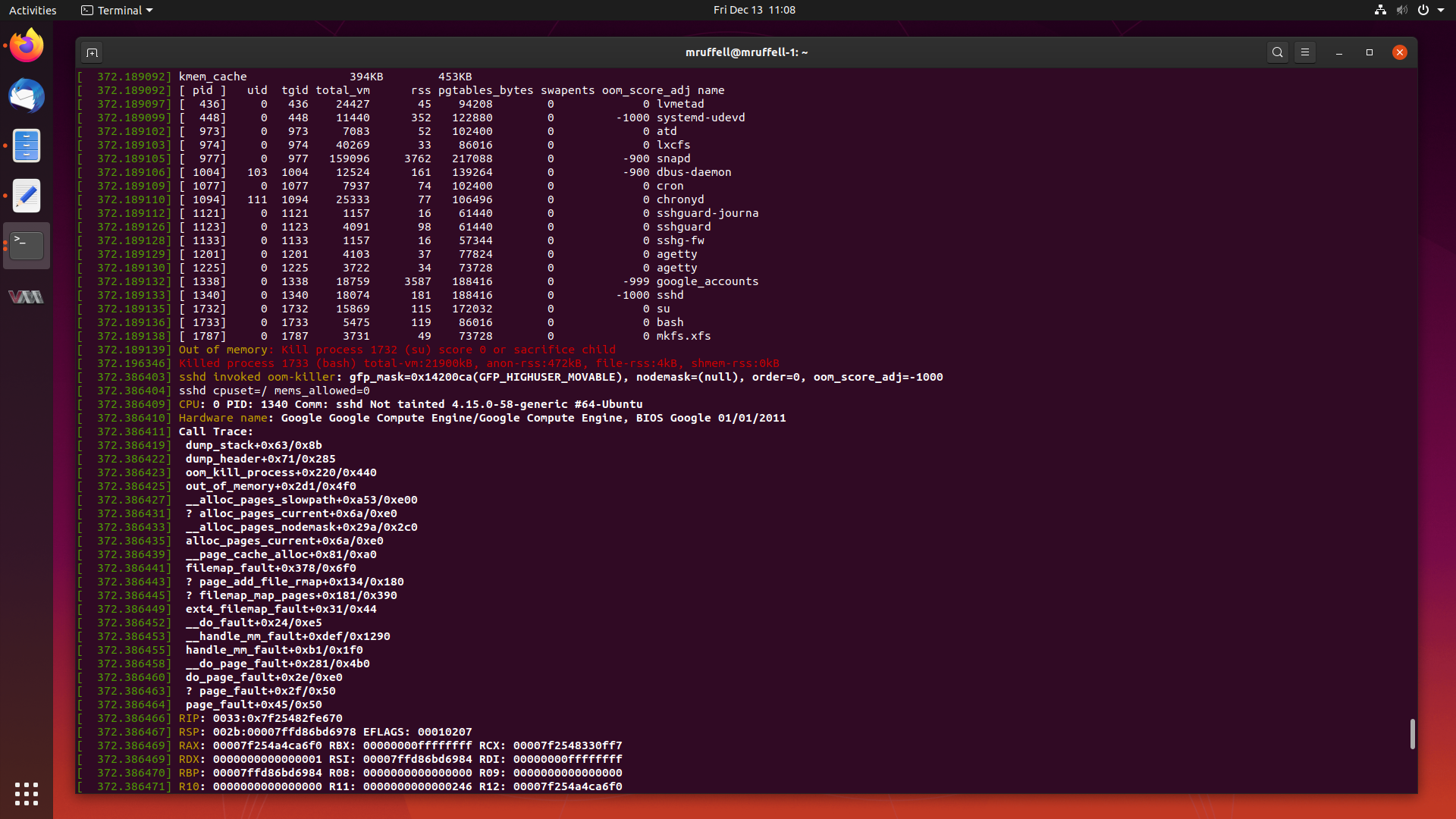
Let’s start digging into this and get this fixed.
-
Learning How to Write Juju Charms by Creating a Minetest Charm 02 Dec 2019
In my previous blog post about Juju, a tool which lets you deploy and scale software easily, we learned what Juju is, how to deploy some common software packages, debug them, and scale them.
Juju deploys Charms, a set of instructions on how to install, configure and scale a particular software package. To be able to deploy software as a Charm, a Charm has to be written first. Usually Charms are written by experts in operating that software package, so that the Charm represents the best way to configure and tune that application. But what happens if no Charm exists for something you want to deploy?
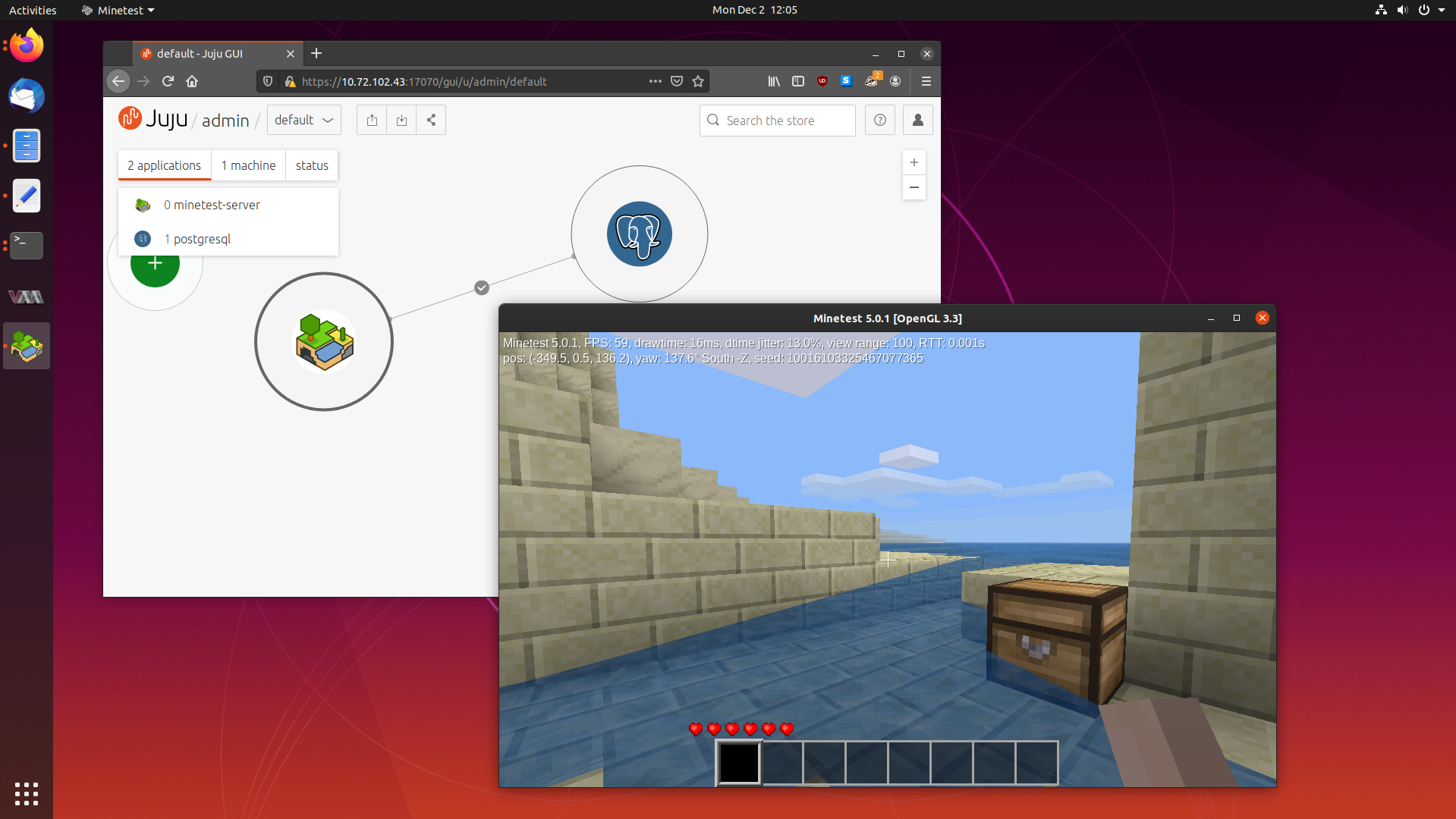
Today we are going to learn how to write our own Charms using the original Charm writing method, by making a Charm for the Minetest game server. So fire up your favourite text editor, and lets get started.
-
Getting Started With Juju to Deploy and Scale Software Effortlessly 26 Aug 2019
The next piece of cloud software which has caught my attention is Juju, a tool which allows you to effortlessly deploy software to any cloud, and scale it with the touch of a button.
Juju deploys software in the form of Charms, a collection of scripts and deployment instructions that implements industry best practices and knowledge about that particular software package.
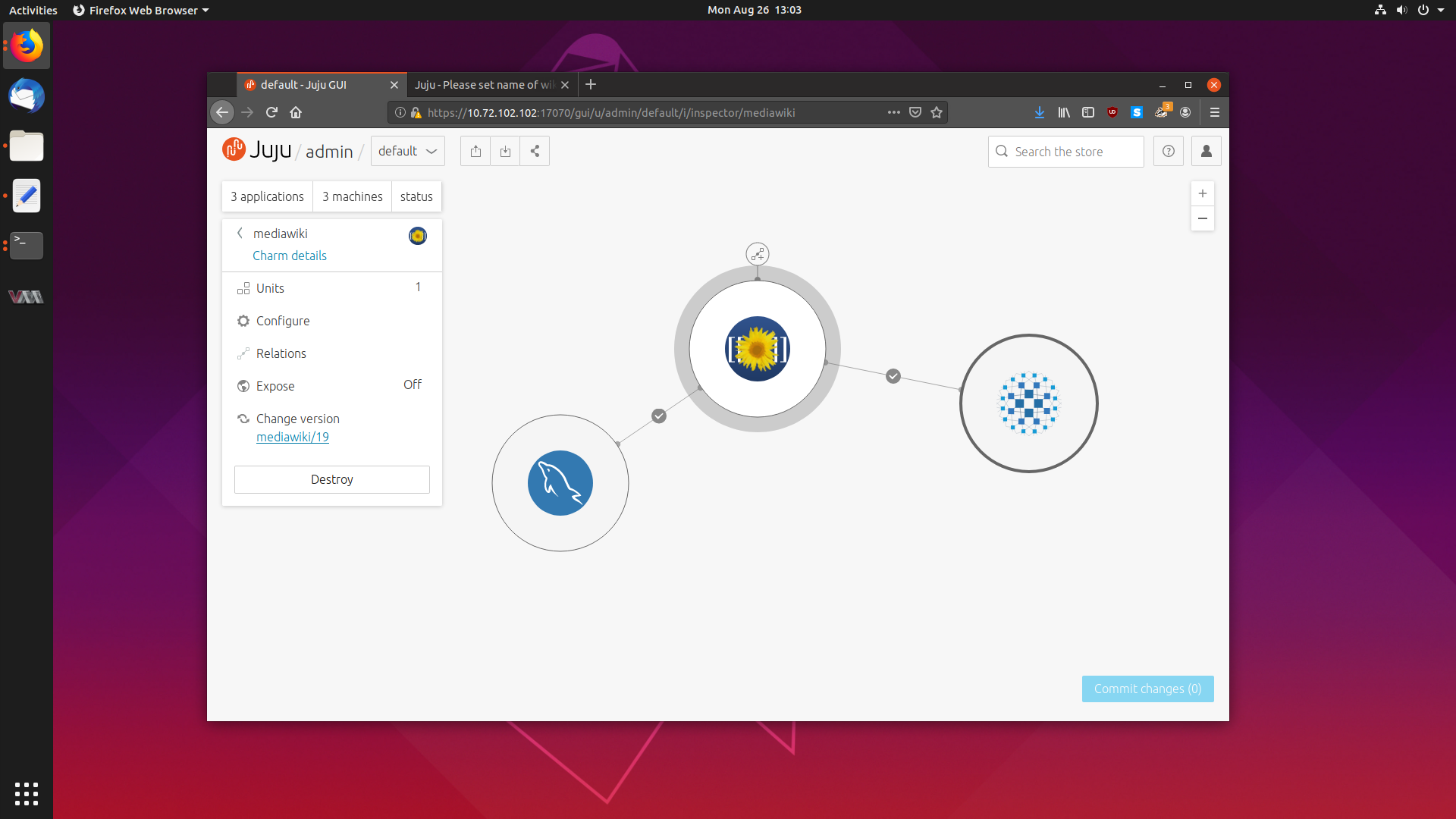
Today we are going to take a deep dive into Juju, and explore how it works, how to set it up and how to deploy and scale some common software.
-
Resolving Large NVMe Performance Degradation in the Ubuntu 4.4 Kernel 20 Jul 2019
Have you ever wondered what a day in the life of a Sustaining Engineer at Canonical looks like?
Well today, we are going to have a look into a particularly interesting case I worked from start to completion, as it demanded that I dive into the world of Linux performance analysis tools to track down and solve the problem.
The problem is that there is a large performance degradation when reading files from a mounted read-only LVM snapshot on the Ubuntu 4.4 kernel, when compared to reading from a standard LVM volume. Reads can take anywhere from 14-25x the amount of time, which is a serious problem.
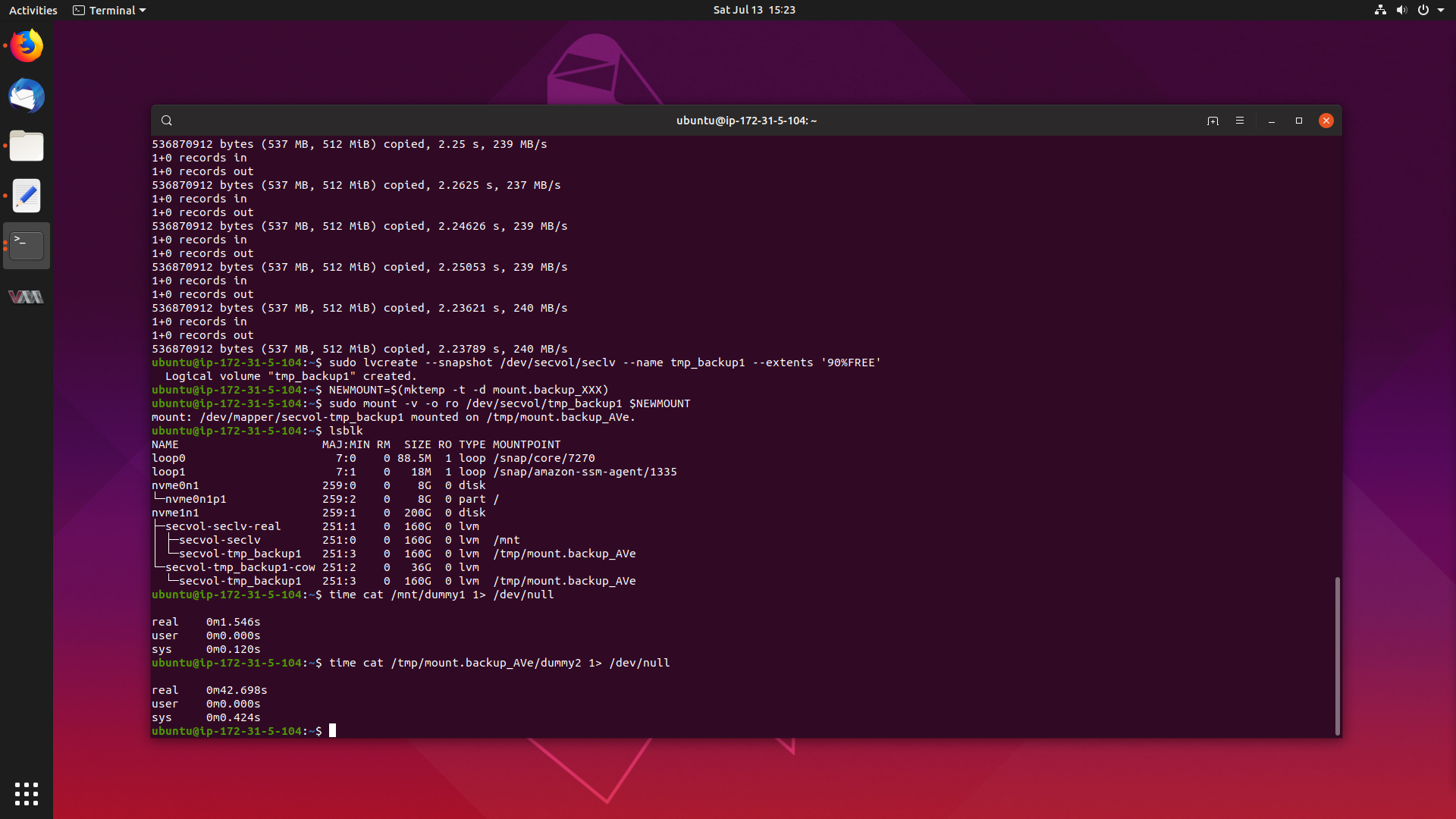
Lets get to the bottom of this, and get this fixed.
-
Deploying a Ceph Cluster in Ubuntu 19.04 17 May 2019
One of the major advancements in recent technology is the rise of cloud computing, and to be perfectly honest with you, I really don’t understand how the whole cloud thing works.
So, I’m going to start a series of blog posts where I will deploy some cloud services, and learn how they work.
Today we will learn how to deploy a Ceph cluster on Ubuntu 19.04 Disco Dingo, so get ready, fire up some VMs with me and follow along.
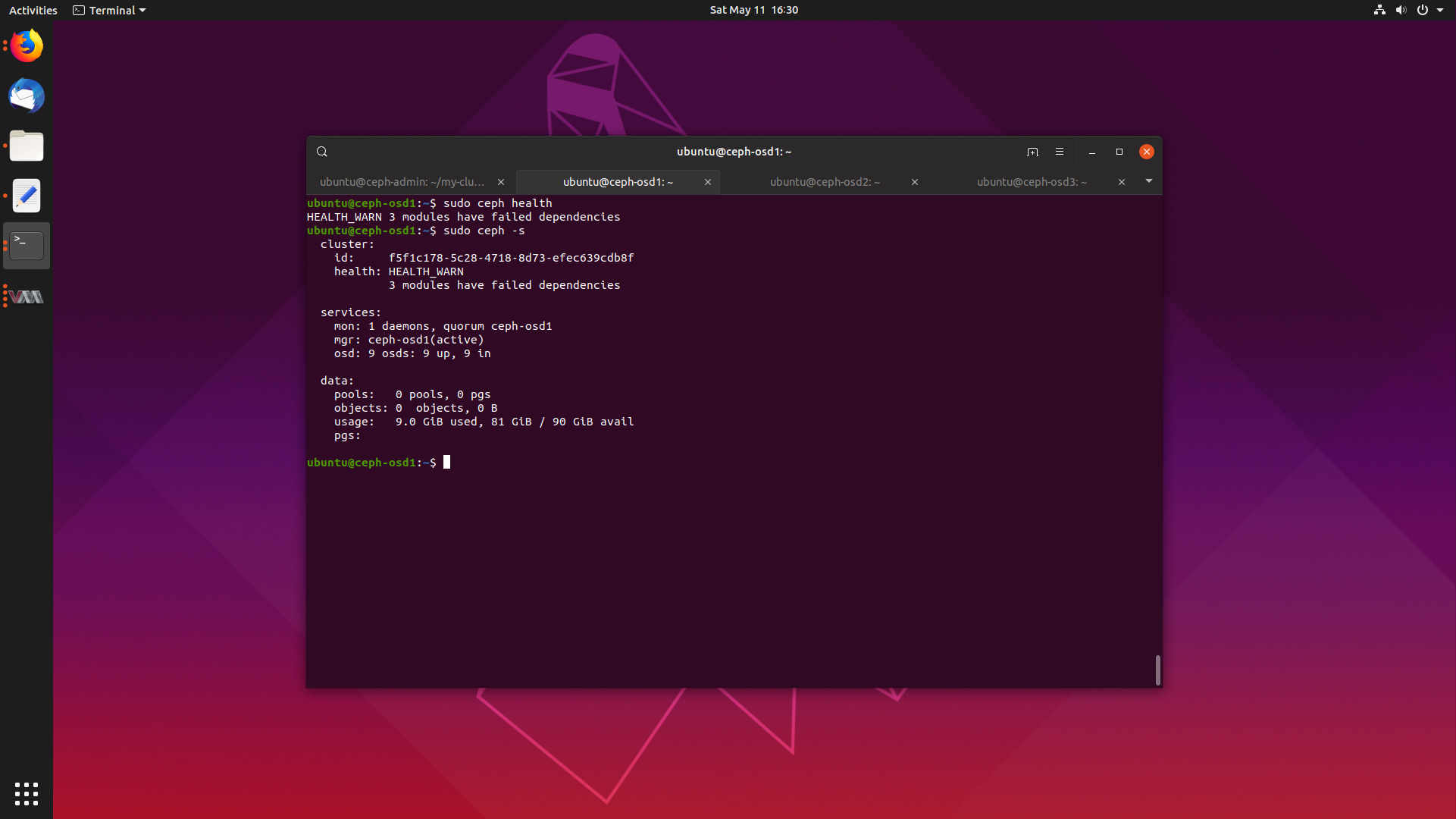
We will cover what Ceph is, how to deploy it, and what it’s primary use cases are.
Let’s get started.
-
Beginning Kernel Crash Debugging on Ubuntu 18.10 22 Feb 2019
If you have been reading this blog, you have probably noticed how all the debugging and analysis of applications have been on Windows executables, and although I did create my own Linux distribution, Dapper Linux, I haven’t written much about debugging on Linux.
Time to change that. Today, we are going to look into how debugging Linux kernel crash dumps works on Ubuntu 18.10 Cosmic Cuttlefish. Fire up a virtual machine, and follow along.
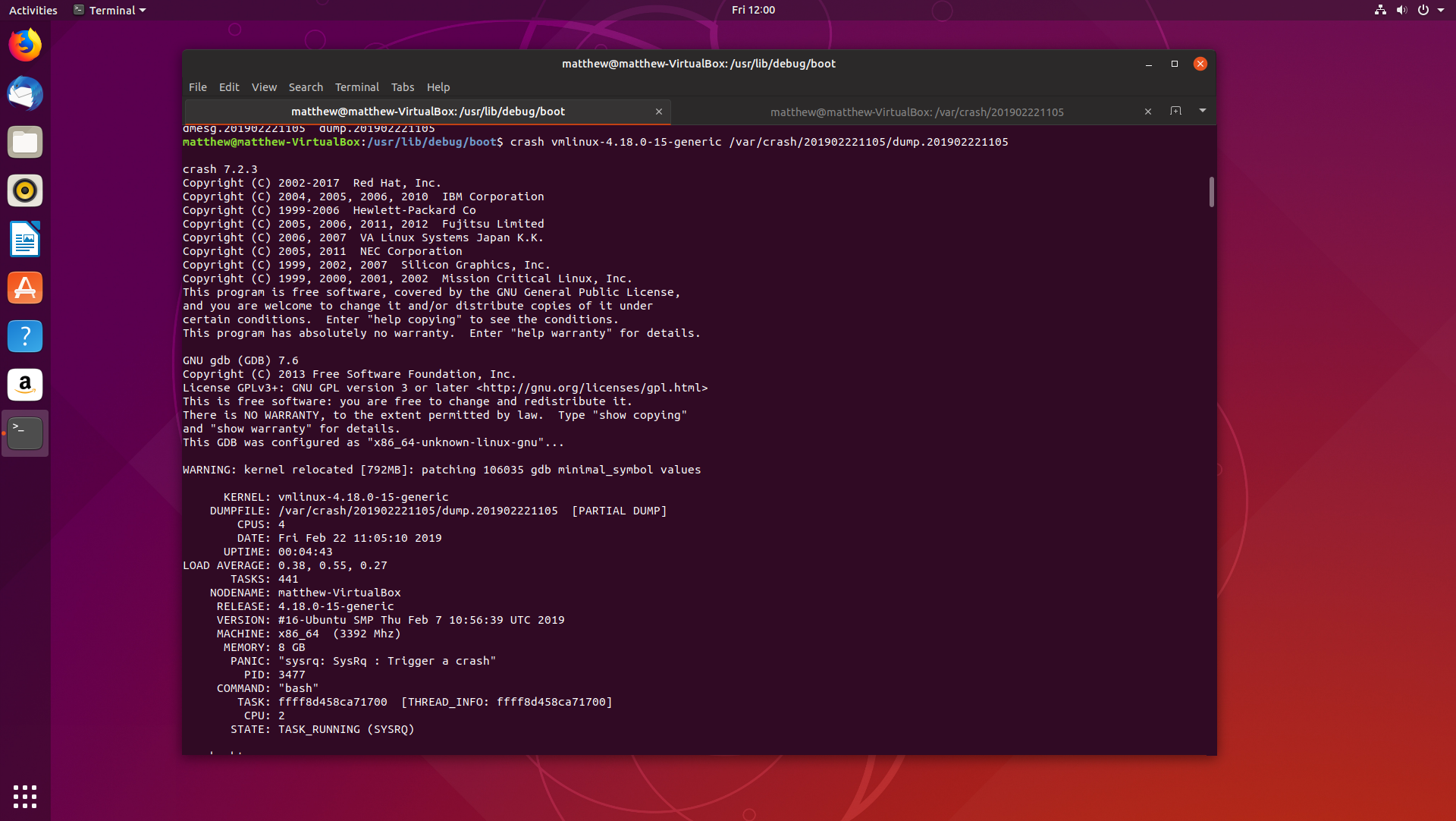
We will cover how to install and configure
crashandkdump, a little on how each tool works, and finding the root cause of a basic panic.Let’s get started.
-
Looking at kmalloc() and the SLUB Memory Allocator 15 Feb 2019
Recently I was asked to do some homework to prepare for an interview on Linux kernel internals, and I was given the following to analyse:
Specifically, we would like you to study and be able to discuss the code path that is exercised when a kernel caller allocates an object from the kernel memory allocator using a call of the form:
object = kmalloc(sizeof(*object), GFP_KERNEL);For this discussion, assume that (a) sizeof(*object) is 128, (b) there is no process context associated with the allocation, and (c) we’re referencing an Ubuntu 4.4 series kernel, as found at
git://kernel.ubuntu.com/ubuntu/ubuntu-xenial.git
In addition, we will discuss the overall architecture of the SLUB allocator and memory management in the kernel, and the specifics of the slab_alloc_node() function in mm/slub.c.
I spent quite a lot of time, maybe 8-10 hours, studying how the SLUB memory allocator functions, and looking at the implementation of
kmalloc(). It’s a pretty interesting process, and it is well worth writing up.Let’s get started, and I will try to keep this simple.