Recently I worked a particularly interesting case where an OpenStack compute node
had all of its virtual machines pause at the same time, which I attributed to
a reference counter overflowing in the kernel’s zero_page.
Today, we are going to take a in-depth look at the problem at hand, and see how I debugged and fixed the issue, from beginning to completion.
Let’s get started.
Problem Description
The first thing to do with any problem is to understand what happened, and gather as much data as possible.
Having a look at the case, the complaint is that a OpenStack compute node running on 16.04 LTS with the Xenial-Queens cloud archive enabled suffered a failure where all virtual machines were paused at once. The node was running the 4.15 Xenial HWE kernel, so this system is more or less built with Bionic components ontop of Xenial.
The logs show various QEMU errors and a crash, as well as a kernel oops. Let’s have a look.
From syslog:
error : qemuMonitorJSONCheckError:392 : internal error: unable to execute QEMU command 'cont': Resetting the Virtual Machine is required
From QEMU Logs:
error: kvm run failed Bad address
EAX=000afe00 EBX=0000000b ECX=00000080 EDX=00000cfe
ESI=0003fe00 EDI=000afe00 EBP=00000007 ESP=00006d74
EIP=000ee344 EFL=00010002 [-------] CPL=0 II=0 A20=1 SMM=0 HLT=0
ES =0010 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
CS =0008 00000000 ffffffff 00c09b00 DPL=0 CS32 [-RA]
SS =0010 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
DS =0010 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
FS =0010 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
GS =0010 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
LDT=0000 00000000 0000ffff 00008200 DPL=0 LDT
TR =0000 00000000 0000ffff 00008b00 DPL=0 TSS32-busy
GDT= 000f7040 00000037
IDT= 000f707e 00000000
CR0=00000011 CR2=00000000 CR3=00000000 CR4=00000000
DR0=0000000000000000 DR1=0000000000000000 DR2=0000000000000000 DR3=0000000000000000
DR6=00000000ffff0ff0 DR7=0000000000000400
EFER=0000000000000000
Code=c3 57 56 b8 00 fe 0a 00 be 00 fe 03 00 b9 80 00 00 00 89 c7 <f3> a5 a1 00 80 03 00 8b 15 04 80 03 00 a3 00 80 0a 00 89 15 04 80 0a 00 b8 ae e2 00 00 31
Finally, the kernel oops:
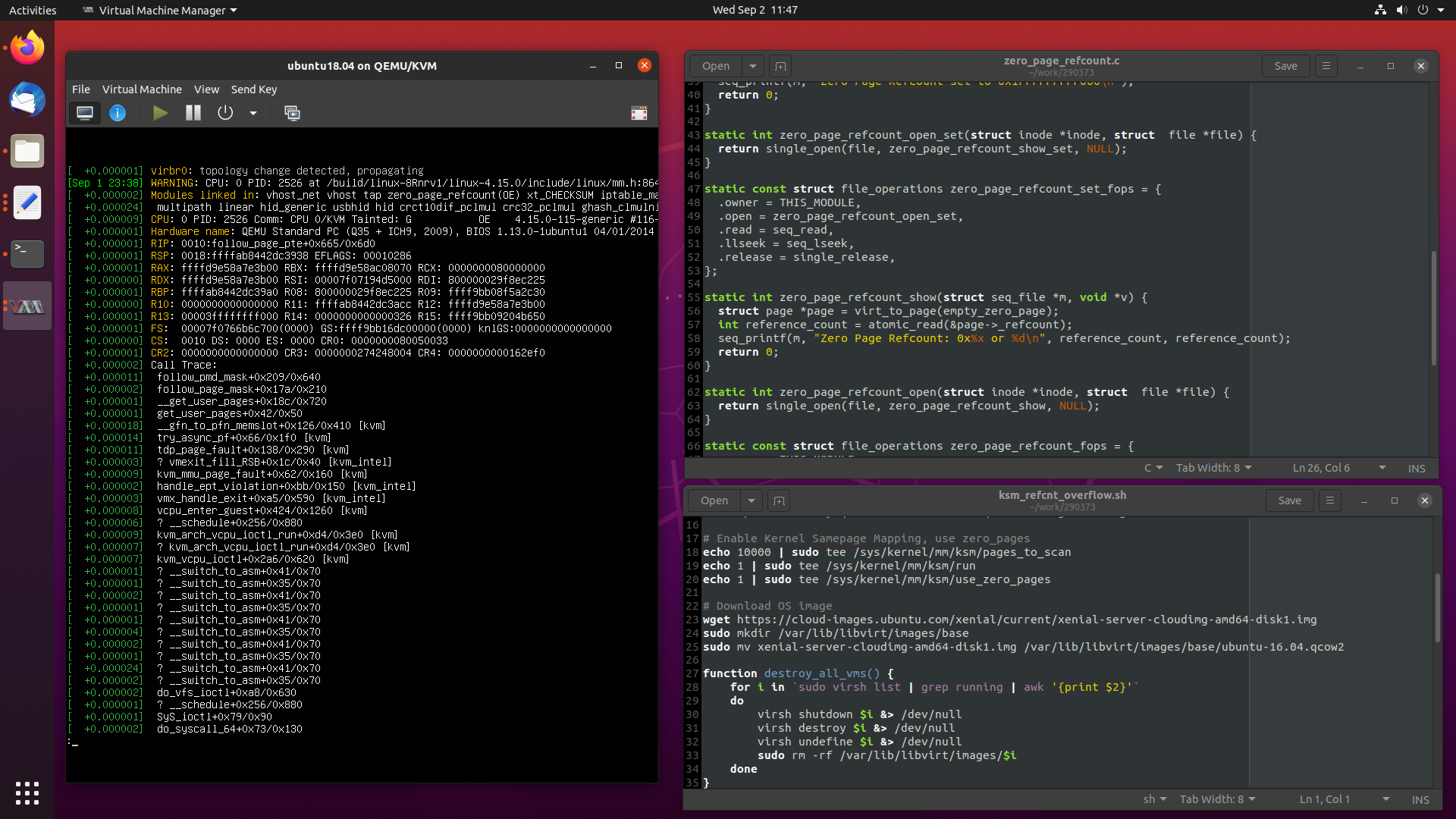
[3191370.893495] WARNING: CPU: 13 PID: 48929 at /build/linux-hwe-FEhT7y/linux-hwe-4.15.0/include/linux/mm.h:852 follow_page_pte+0x6f4/0x710
[3191370.893552] CPU: 13 PID: 48929 Comm: CPU 0/KVM Not tainted 4.15.0-106-generic #107~16.04.1-Ubuntu
[3191370.893552] Hardware name: Dell Inc. PowerEdge R740xd/00WGD1, BIOS 2.6.4 04/09/2020
[3191370.893554] RIP: 0010:follow_page_pte+0x6f4/0x710
[3191370.893555] RSP: 0018:ffffad279f7ab908 EFLAGS: 00010286
[3191370.893556] RAX: ffffdc0fa72eba80 RBX: ffffdc0f9b1535b0 RCX: 0000000080000000
[3191370.893556] RDX: 0000000000000000 RSI: 00003ffffffff000 RDI: 800000b9cbaea225
[3191370.893557] RBP: ffffad279f7ab970 R08: 800000b9cbaea225 R09: ffff9359857fd5f0
[3191370.893558] R10: 0000000000000000 R11: 0000000000000000 R12: ffffdc0fa72eba80
[3191370.893558] R13: 0000000000000326 R14: ffff935de09e19e0 R15: ffff9359857fd5f0
[3191370.893559] FS: 00007f68757fa700(0000) GS:ffff93617ef80000(0000) knlGS:ffff964a7fc00000
[3191370.893559] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[3191370.893560] CR2: 00007ff92ca7a000 CR3: 000000b7209d2005 CR4: 00000000007626e0
[3191370.893561] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[3191370.893561] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
[3191370.893561] PKRU: 55555554
[3191370.893562] Call Trace:
[3191370.893565] follow_pmd_mask+0x273/0x630
[3191370.893567] ? gup_pgd_range+0x23f/0xde0
[3191370.893568] follow_page_mask+0x178/0x230
[3191370.893569] __get_user_pages+0xb8/0x740
[3191370.893571] get_user_pages+0x42/0x50
[3191370.893604] __gfn_to_pfn_memslot+0x18b/0x3b0 [kvm]
[3191370.893615] ? mmu_set_spte+0x1dd/0x3a0 [kvm]
[3191370.893626] try_async_pf+0x66/0x220 [kvm]
[3191370.893635] tdp_page_fault+0x14b/0x2b0 [kvm]
[3191370.893640] ? vmexit_fill_RSB+0x10/0x40 [kvm_intel]
[3191370.893649] kvm_mmu_page_fault+0x62/0x180 [kvm]
[3191370.893651] handle_ept_violation+0xbc/0x160 [kvm_intel]
[3191370.893654] vmx_handle_exit+0xa5/0x580 [kvm_intel]
[3191370.893664] vcpu_enter_guest+0x414/0x1260 [kvm]
[3191370.893674] kvm_arch_vcpu_ioctl_run+0xd9/0x3d0 [kvm]
[3191370.893683] ? kvm_arch_vcpu_ioctl_run+0xd9/0x3d0 [kvm]
[3191370.893691] kvm_vcpu_ioctl+0x33a/0x610 [kvm]
[3191370.893693] ? audit_filter_rules+0x232/0x1070
[3191370.893696] do_vfs_ioctl+0xa4/0x600
[3191370.893697] ? __audit_syscall_entry+0xac/0x100
[3191370.893699] ? syscall_trace_enter+0x1d6/0x2f0
[3191370.893700] SyS_ioctl+0x79/0x90
[3191370.893701] do_syscall_64+0x73/0x130
[3191370.893704] entry_SYSCALL_64_after_hwframe+0x3d/0xa2
[3191370.893705] RIP: 0033:0x7f68c81b4f47
[3191370.893706] RSP: 002b:00007f68757f98b8 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
[3191370.893707] RAX: ffffffffffffffda RBX: 000000000000ae80 RCX: 00007f68c81b4f47
[3191370.893707] RDX: 0000000000000000 RSI: 000000000000ae80 RDI: 0000000000000031
[3191370.893708] RBP: 000055ac785ae320 R08: 000055ac77357310 R09: 00000000000000ff
[3191370.893708] R10: 0000000000000001 R11: 0000000000000246 R12: 0000000000000000
[3191370.893708] R13: 00007f68cd582000 R14: 0000000000000000 R15: 000055ac785ae320
[3191370.893709] Code: 4d 63 e6 e9 f2 fc ff ff 4c 89 45 d0 48 8b 47 10 e8 22 f0 9e 00 4c 8b 45 d0 e9 89 fc ff ff 4c 89 e7 e8 81 3f fd ff e9 aa fc ff ff <0f> 0b 49 c7 c4 f4 ff ff ff e9 c1 fc ff ff 0f 1f 40 00 66 2e 0f
Since the kernel oops mentions a few functions in the KVM module, and we know that all VMs were paused at the same time, we are probably looking at a kernel problem and not a problem in QEMU or OpenStack.
Looking at the system time, 3191370 seconds is 36.93 days, which is quite a long time, so this fault is likely something that takes time to hit. Time to start digging.
Analysis of Kernel Oops
Looking at the call trace in the kernel oops, we see that an EPT (Extended Page
Table) violation has happened, with the call to handle_ept_violation()
in the kvm_intel module.
Right after that, we page fault with kvm_mmu_page_fault(), which calls
tdp_page_fault().
From there, the kernel goes on a goose chase to try locate a particular page,
with calls to get_user_pages(), follow_page_mask(), gup_pgd_range() and
follow_pmd_mask().
We crash at follow_page_pte+0x6f4, which is mentioned in RIP.
Okay, so the next step is to read the code at follow_page_pte+0x6f4, so we
download the debug kernel ddeb, for Xenial HWE, and save it to disk.
From there we can extract it, and query the file and line of code with eu-addr2line:
$ dpkg -x linux-image-unsigned-4.15.0-106-generic-dbgsym_4.15.0-106.107~16.04.1_amd64.ddeb linux
$ cd linux/usr/lib/debug/boot
$ eu-addr2line -e ./vmlinux-4.15.0-106-generic -f follow_page_pte+0x6f4
try_get_page inlined at /build/linux-hwe-FEhT7y/linux-hwe-4.15.0/mm/gup.c:156 in follow_page_pte
/build/linux-hwe-FEhT7y/linux-hwe-4.15.0/mm/gup.c:170
Okay, this is interesting. Let’s jump to mm/gup.c:156 in the 4.15 kernel source
tree, and see we are in follow_page_pte():
73 static struct page *follow_page_pte(struct vm_area_struct *vma,
74 unsigned long address, pmd_t *pmd, unsigned int flags)
75 {
...
155 if (flags & FOLL_GET) {
156 if (unlikely(!try_get_page(page))) {
157 page = ERR_PTR(-ENOMEM);
158 goto out;
159 }
...
See the call to try_get_page()? It was actually mentioned in the eu-addr2line
output, as it mentions that we are executing an inlined try_get_page().
Lets look up try_get_page(). try_get_page() is located in include/linux/mm.h:852,
which is mentioned at the top of the oops message:
849 static inline __must_check bool try_get_page(struct page *page)
850 {
851 page = compound_head(page);
852 if (WARN_ON_ONCE(page_ref_count(page) <= 0))
853 return false;
854 page_ref_inc(page);
855 return true;
856 }
if (WARN_ON_ONCE(page_ref_count(page) <= 0)) looks like a check to ensure that
this page’s reference counter has not overflowed and wrapped around into negatives.
If we hit this warning and oopsed, then we must have overflowed the page’s reference counter somehow. We now need to figure out which page, and why.
Finding the Commit with the Fix
At this point, I did some searching on some mailing lists, and the upstream kernel git tree. I got lucky and came across the below commit rather quickly:
commit 7df003c85218b5f5b10a7f6418208f31e813f38f
Author: Zhuang Yanying <[email protected]>
Date: Sat Oct 12 11:37:31 2019 +0800
Subject: KVM: fix overflow of zero page refcount with ksm running
Link: https://github.com/torvalds/linux/commit/7df003c85218b5f5b10a7f6418208f31e813f38f
The description mentions that the patch authors were testing starting and
stopping virtual machines with Kernel Samepage Mapping (KSM) enabled on the
compute node. They found a reference counter overflow on the zero_page,
as the counter gets incremented in try_async_pf(), which is present in our
call trace, while not being decremented in mmu_set_spte(), which is also present,
while handling an EPT violation.
Kernel Samepage Mapping is a kernel feature that allows pages to be merged into each other, and is used in KVM. It allows you to overload the memory of a compute node, for example, 100GB of ram on a node with only 64GB of ram. It works by merging the “same” pages together across different virtual machines.
In this case, the problem is centred around the zero_page, which is special,
as it is a reserved page. If you allocate a new virtual machine, it will allocate
many new pages full of zeros. To save space, these pages aren’t actually allocated.
Instead, we use zero_page. The zero_page is a page full of zeros. For each
would be newly allocated page that would be full of zeros, we simply set them
to reference the zero_page. This increments the zero_page reference counter.
When the VM wants to write data to one of those pages, a EPT violation happens, and we page fault. This triggers a copy-on-write (COW) action, that allocates a new page where the data can be written to.
In this case, each time we enter try_async_pf() we increment the reference
counter for the zero_page, but it never gets decremented.
The commit description also includes a kernel oops and QEMU crash log, and it very closely matches what we found in the OpenStack compute node.
Looking at the logs from the compute node, we also see that KSM is enabled on the system:
$ cat sosreport/sys/kernel/mm/ksm/run
1
Looks like we have our root cause.
The fix itself is pretty simple:
diff --git a/virt/kvm/kvm_main.c b/virt/kvm/kvm_main.c
index 7e63a32363640..67ae2d5c37b23 100644
--- a/virt/kvm/kvm_main.c
+++ b/virt/kvm/kvm_main.c
@@ -186,6 +186,7 @@ bool kvm_is_reserved_pfn(kvm_pfn_t pfn)
*/
if (pfn_valid(pfn))
return PageReserved(pfn_to_page(pfn)) &&
+ !is_zero_pfn(pfn) &&
!kvm_is_zone_device_pfn(pfn);
return true;
The fix stops treating the zero_page as reserved in kvm_is_reserved_pfn()
which seems to prevent the reference counter from being incremented in higher
functions.
Attempting to Reproduce the Problem
At this point, I went and built a test kernel based on 4.15.0-106-generic and included the commit we found. But we now need to reproduce the problem to prove that the commit actually fixes the problem.
The commit mentions some instructions on how to reproduce the problem:
step1:
echo 10000 > /sys/kernel/pages_to_scan/pages_to_scan
echo 1 > /sys/kernel/pages_to_scan/run
echo 1 > /sys/kernel/pages_to_scan/use_zero_pages
step2:
just create several normal qemu kvm vms.
And destroy it after 10s.
Repeat this action all the time.
Okay, so it ups the number of pages to scan, enables KSM and the use_zero_pages
feature. From there I need to create and destroy a bunch of virtual machines
in a loop. It doesn’t sound too hard.
If we remember the OpenStack compute node’s uptime of 37 days, and that the reference counter is a signed integer, which means we would need ~2.5 billion increments to wrap the reference counter into negatives, with a 32 bit atomic_t variable.
This might take a while.
I wrote a script that uses libvirt to create and destroy virtual machines, which runs more or less forever:
#!/bin/bash
# Script to start and stop KVM virtual machines to try trigger Kernel Samepage
# Mapping zero_page reference counter overflow.
#
# Author: Matthew Ruffell <[email protected]>
# BugLink: https://bugs.launchpad.net/bugs/1837810
#
# Fix: https://github.com/torvalds/linux/commit/7df003c85218b5f5b10a7f6418208f31e813f38f
#
# Instructions:
# ./ksm_refcnt_overflow.sh
# Install QEMU KVM if needed
sudo apt install -y qemu-kvm libvirt-bin qemu-utils genisoimage virtinst
# Enable Kernel Samepage Mapping, use zero_pages
echo 10000 | sudo tee /sys/kernel/mm/ksm/pages_to_scan
echo 1 | sudo tee /sys/kernel/mm/ksm/run
echo 1 | sudo tee /sys/kernel/mm/ksm/use_zero_pages
# Download OS image
wget https://cloud-images.ubuntu.com/xenial/current/xenial-server-cloudimg-amd64-disk1.img
sudo mkdir /var/lib/libvirt/images/base
sudo mv xenial-server-cloudimg-amd64-disk1.img /var/lib/libvirt/images/base/ubuntu-16.04.qcow2
function destroy_all_vms() {
for i in `sudo virsh list | grep running | awk '{print $2}'`
do
virsh shutdown $i &> /dev/null
virsh destroy $i &> /dev/null
virsh undefine $i &> /dev/null
sudo rm -rf /var/lib/libvirt/images/$i
done
}
function create_single_vm() {
sudo mkdir /var/lib/libvirt/images/instance-$1
sudo cp /var/lib/libvirt/images/base/ubuntu-16.04.qcow2 /var/lib/libvirt/images/instance-$1/instance-$1.qcow2
virt-install --connect qemu:///system \
--virt-type kvm \
--name instance-$1 \
--ram 1024 \
--vcpus=1 \
--os-type linux \
--os-variant ubuntu16.04 \
--disk path=/var/lib/libvirt/images/instance-$1/instance-$1.qcow2,format=qcow2 \
--import \
--network network=default \
--noautoconsole &> /dev/null
}
function create_destroy_loop() {
NUM="0"
while true
do
NUM=$[$NUM + 1]
echo "Run #$NUM"
for i in {0..7}
do
create_single_vm $i
echo "Created instance $i"
sleep 10
done
sleep 30
echo "Destroying all VMs"
destroy_all_vms
done
}
create_destroy_loop
You can download the script here.
The script makes sure that KSM is enabled, it installs and sets up KVM, and gets busy creating and destroying virtual machines every 10 seconds or so.
I provisioned a lab machine that was a bit more beefy than usual and started running the script.
I left the lab machine running for a few days, and I checked it every day to see if it had crashed, or if it was happily creating and destroying virtual machines.
After about 3 or 4 days I got a bit bored, and started wondering if we could see the value of the zero_page reference counter to try and see how far along we are to overflow.
I was talking to some colleagues, and one mentioned that I should be able to use
crash to view live kernel memory, as long as I have the right debug kernel.
So, I installed crash and the debug kernel on the lab machine, and had a look.
Looking at the kernel source code, it seems the kernel allocated the zero_page
as empty_zero_page, in arch/x86/include/asm/pgtable.h:
43 /*
44 * ZERO_PAGE is a global shared page that is always zero: used
45 * for zero-mapped memory areas etc..
46 */
47 extern unsigned long empty_zero_page[PAGE_SIZE / sizeof(unsigned long)]
48 __visible;
49 #define ZERO_PAGE(vaddr) (virt_to_page(empty_zero_page))
We can look up the memory address of empty_zero_page with:
crash> x/gx empty_zero_page
0xffffffff9c2ec000: 0x0000000000000000
The memory address is 0xffffffff9c2ec000, and the pointer points to zero,
which would be the first element of the zero page, which makes sense.
The next thing to do, is to try and get the populated struct page for
empty_zero_page.
It turns out that its pretty easy in crash, we can use kmem:
crash> kmem 0xffffffff9c2ec000
ffffffff9c2ec000 (b) .bss
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
ffffd85a125e3b00 4978ec000 0 0 3518835 17ffffc0000800 reserved
The CNT variable is the reference counter for the page struct. In this case,
its only 3518835, which is pretty low. It will take months for this to reach
~2.5 billion and overflow.
In the meantime, if we run the kmem command a few more times:
crash> kmem 0xffffffff9c2ec000
ffffffff9c2ec000 (b) .bss
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
ffffd85a125e3b00 4978ec000 0 0 3525496 17ffffc0000804 referenced,reserved
crash> kmem 0xffffffff9c2ec000
ffffffff9c2ec000 (b) .bss
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
ffffd85a125e3b00 4978ec000 0 0 3546258 17ffffc0000804 referenced,reserved
We can see CNT increase from 3518835 -> 3525496 -> 3546258. It is steadily
increasing, and never gets smaller. So we can see buggy behaviour, but we
can’t reproduce the failure just yet.
Working Smarter and Reproducing by Writing a Kernel Module
Okay, so we need a way to be able to reproduce the problem faster than just
waiting for it to happen. In this case, we are going to write a kernel module
to read, and hopefully set the value of the reference counter of the zero_page.
One of my colleagues told me that I can get the page struct for the zero_page
by calling virt_to_page() and passing in empty_zero_page. This is useful,
as the reference counter is the _refcount member, as shown below:
If we look at include/linux/mm_types.h:
42 struct page {
...
81 struct {
82
83 union {
84 /*
85 * Count of ptes mapped in mms, to show when
86 * page is mapped & limit reverse map searches.
87 *
88 * Extra information about page type may be
89 * stored here for pages that are never mapped,
90 * in which case the value MUST BE <= -2.
91 * See page-flags.h for more details.
92 */
93 atomic_t _mapcount;
94
95 unsigned int active; /* SLAB */
96 struct { /* SLUB */
97 unsigned inuse:16;
98 unsigned objects:15;
99 unsigned frozen:1;
100 };
101 int units; /* SLOB */
102 };
103 /*
104 * Usage count, *USE WRAPPER FUNCTION* when manual
105 * accounting. See page_ref.h
106 */
107 atomic_t _refcount;
108 };
109 };
_refcount is what we are interested in, since if we remember back to
try_get_page() and its call to if (WARN_ON_ONCE(page_ref_count(page) <= 0)),
we can look at the implementation of page_ref_count() in include/linux/page_ref.h:
65 static inline int page_ref_count(struct page *page)
66 {
67 return atomic_read(&page->_refcount);
68 }
This just does a atomic_read() on page struct -> _refcount.
Good! Let’s write a kernel module which exposes a /proc interface which we
can read from, to see the current value of the zero_page reference counter:
/*
* zero_page_refcount.c - view zero_page reference counter in real time
* with the proc filesystem.
*
* Author: Matthew Ruffell <[email protected]>
*
* Steps:
*
* $ sudo apt-get -y install gcc make libelf-dev linux-headers-$(uname -r)
*
* cat <<EOF >Makefile
obj-m=zero_page_refcount.o
KVER=\$(shell uname -r)
MDIR=\$(shell pwd)
default:
$(echo -e '\t')make -C /lib/modules/\$(KVER)/build M=\$(MDIR) modules
clean:
$(echo -e '\t')make -C /lib/modules/\$(KVER)/build M=\$(MDIR) clean
EOF
*
* $ make
* $ sudo insmod zero_page_refcount.ko
* # To display current zero_page reference count:
* $ cat /proc/zero_page_refcount
*/
#include <linux/module.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>
#include <linux/atomic.h>
#include <asm/pgtable.h>
static int zero_page_refcount_show(struct seq_file *m, void *v) {
struct page *page = virt_to_page(empty_zero_page);
int reference_count = atomic_read(&page->_refcount);
seq_printf(m, "Zero Page Refcount: 0x%x or %d\n", reference_count, reference_count);
return 0;
}
static int zero_page_refcount_open(struct inode *inode, struct file *file) {
return single_open(file, zero_page_refcount_show, NULL);
}
static const struct file_operations zero_page_refcount_fops = {
.owner = THIS_MODULE,
.open = zero_page_refcount_open,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
static int __init zero_page_refcount_init(void) {
proc_create("zero_page_refcount", 0, NULL, &zero_page_refcount_fops);
return 0;
}
static void __exit zero_page_refcount_exit(void) {
remove_proc_entry("zero_page_refcount", NULL);
}
MODULE_LICENSE("GPL");
module_init(zero_page_refcount_init);
module_exit(zero_page_refcount_exit);
The module is pretty simple, we register a /proc interface called
/proc/zero_page_refcount, which is read-only. It calls the module function
zero_page_refcount_show(), which uses virt_to_page(empty_zero_page) to get
the page struct for the zero page, we do an atomic_read(&page->_refcount)
to get the reference counter, and we then print it out. Easy as.
If you compile it with the following Makefile:
obj-m=zero_page_refcount.o
KVER=\$(shell uname -r)
MDIR=\$(shell pwd)
default:
make -C /lib/modules/\$(KVER)/build M=\$(MDIR) modules
clean:
make -C /lib/modules/\$(KVER)/build M=\$(MDIR) clean
with:
$ make
$ sudo insmod zero_page_refcount.ko
From there we can run it with:
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x687 or 1671
If we run it a few times, we can see it increment.
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x687 or 1671
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x846 or 2118
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x9f8 or 2552
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0xcb2 or 3250
Okay, so our kernel module works. Now, we can go about writing a function to
set the value of the reference counter. I just added another /proc interface,
called /proc/zero_page_refcount_set which uses virt_to_page(empty_zero_page)
to get the page struct, and atomic_set(&page->_refcount, 0xFFFF7FFFFF00) to
set it near overflow.
The complete module is below:
/*
* zero_page_refcount.c - view zero_page reference counter in real time
* with the proc filesystem.
*
* Author: Matthew Ruffell <[email protected]>
*
* Steps:
*
* $ sudo apt-get -y install gcc make libelf-dev linux-headers-$(uname -r)
*
* cat <<EOF >Makefile
obj-m=zero_page_refcount.o
KVER=\$(shell uname -r)
MDIR=\$(shell pwd)
default:
$(echo -e '\t')make -C /lib/modules/\$(KVER)/build M=\$(MDIR) modules
clean:
$(echo -e '\t')make -C /lib/modules/\$(KVER)/build M=\$(MDIR) clean
EOF
*
* $ make
* $ sudo insmod zero_page_refcount.ko
* # To display current zero_page reference count:
* $ cat /proc/zero_page_refcount
* # To set zero_page reference count to near overflow:
* $ cat /proc/zero_page_refcount_set
*/
#include <linux/module.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>
#include <linux/atomic.h>
#include <asm/pgtable.h>
static int zero_page_refcount_show_set(struct seq_file *m, void *v) {
struct page *page = virt_to_page(empty_zero_page);
atomic_set(&page->_refcount, 0xFFFF7FFFFF00);
seq_printf(m, "Zero Page Refcount set to 0x1FFFFFFFFF000\n");
return 0;
}
static int zero_page_refcount_open_set(struct inode *inode, struct file *file) {
return single_open(file, zero_page_refcount_show_set, NULL);
}
static const struct file_operations zero_page_refcount_set_fops = {
.owner = THIS_MODULE,
.open = zero_page_refcount_open_set,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
static int zero_page_refcount_show(struct seq_file *m, void *v) {
struct page *page = virt_to_page(empty_zero_page);
int reference_count = atomic_read(&page->_refcount);
seq_printf(m, "Zero Page Refcount: 0x%x or %d\n", reference_count, reference_count);
return 0;
}
static int zero_page_refcount_open(struct inode *inode, struct file *file) {
return single_open(file, zero_page_refcount_show, NULL);
}
static const struct file_operations zero_page_refcount_fops = {
.owner = THIS_MODULE,
.open = zero_page_refcount_open,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
static int __init zero_page_refcount_init(void) {
proc_create("zero_page_refcount", 0, NULL, &zero_page_refcount_fops);
proc_create("zero_page_refcount_set", 0, NULL, &zero_page_refcount_set_fops);
return 0;
}
static void __exit zero_page_refcount_exit(void) {
remove_proc_entry("zero_page_refcount", NULL);
remove_proc_entry("zero_page_refcount_set", NULL);
}
MODULE_LICENSE("GPL");
module_init(zero_page_refcount_init);
module_exit(zero_page_refcount_exit);
You can download the completed module here.
This time, if we build and insert it to the running kernel, we can set the reference counter to near overflow:
$ cat /proc/zero_page_refcount_set
Zero Page Refcount set to 0x1FFFFFFFFF000
After that, we can watch it overflow:
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x7fffff16 or 2147483414
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x80000000 or -2147483648
See that? It wrapped around from 2147483414 to -2147483648! That’s a signed integer overflow.
If we check the status of our virtual machines, still running in that infinite script, we see they are now paused:
$ virsh list
Id Name State
----------------------------------------------------
1 instance-0 paused
2 instance-1 paused
If we check dmesg, we see the exact same kernel oops:
[ 167.695986] WARNING: CPU: 1 PID: 3016 at /build/linux-hwe-FEhT7y/linux-hwe-4.15.0/include/linux/mm.h:852 follow_page_pte+0x6f4/0x710
[ 167.696023] CPU: 1 PID: 3016 Comm: CPU 0/KVM Tainted: G OE 4.15.0-106-generic #107~16.04.1-Ubuntu
[ 167.696023] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.13.0-1ubuntu1 04/01/2014
[ 167.696025] RIP: 0010:follow_page_pte+0x6f4/0x710
[ 167.696026] RSP: 0018:ffffa81802023908 EFLAGS: 00010286
[ 167.696027] RAX: ffffed8786e33a80 RBX: ffffed878c6d21b0 RCX: 0000000080000000
[ 167.696027] RDX: 0000000000000000 RSI: 00003ffffffff000 RDI: 80000001b8cea225
[ 167.696028] RBP: ffffa81802023970 R08: 80000001b8cea225 R09: ffff90c4d55fa340
[ 167.696028] R10: 0000000000000000 R11: 0000000000000000 R12: ffffed8786e33a80
[ 167.696029] R13: 0000000000000326 R14: ffff90c4db94fc50 R15: ffff90c4d55fa340
[ 167.696030] FS: 00007f6a7798c700(0000) GS:ffff90c4edc80000(0000) knlGS:0000000000000000
[ 167.696030] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 167.696031] CR2: 0000000000000000 CR3: 0000000315580002 CR4: 0000000000162ee0
[ 167.696033] Call Trace:
[ 167.696047] follow_pmd_mask+0x273/0x630
[ 167.696049] follow_page_mask+0x178/0x230
[ 167.696051] __get_user_pages+0xb8/0x740
[ 167.696052] get_user_pages+0x42/0x50
[ 167.696068] __gfn_to_pfn_memslot+0x18b/0x3b0 [kvm]
[ 167.696079] ? mmu_set_spte+0x1dd/0x3a0 [kvm]
[ 167.696090] try_async_pf+0x66/0x220 [kvm]
[ 167.696101] tdp_page_fault+0x14b/0x2b0 [kvm]
[ 167.696104] ? vmexit_fill_RSB+0x10/0x40 [kvm_intel]
[ 167.696114] kvm_mmu_page_fault+0x62/0x180 [kvm]
[ 167.696117] handle_ept_violation+0xbc/0x160 [kvm_intel]
[ 167.696119] vmx_handle_exit+0xa5/0x580 [kvm_intel]
[ 167.696129] vcpu_enter_guest+0x414/0x1260 [kvm]
[ 167.696138] ? kvm_arch_vcpu_load+0x4d/0x280 [kvm]
[ 167.696148] kvm_arch_vcpu_ioctl_run+0xd9/0x3d0 [kvm]
[ 167.696157] ? kvm_arch_vcpu_ioctl_run+0xd9/0x3d0 [kvm]
[ 167.696165] kvm_vcpu_ioctl+0x33a/0x610 [kvm]
[ 167.696166] ? do_futex+0x129/0x590
[ 167.696171] ? __switch_to+0x34c/0x4e0
[ 167.696174] ? __switch_to_asm+0x35/0x70
[ 167.696176] do_vfs_ioctl+0xa4/0x600
[ 167.696177] SyS_ioctl+0x79/0x90
[ 167.696180] ? exit_to_usermode_loop+0xa5/0xd0
[ 167.696181] do_syscall_64+0x73/0x130
[ 167.696182] entry_SYSCALL_64_after_hwframe+0x3d/0xa2
[ 167.696184] RIP: 0033:0x7f6a80482007
[ 167.696184] RSP: 002b:00007f6a7798b8b8 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
[ 167.696185] RAX: ffffffffffffffda RBX: 000000000000ae80 RCX: 00007f6a80482007
[ 167.696185] RDX: 0000000000000000 RSI: 000000000000ae80 RDI: 0000000000000016
[ 167.696186] RBP: 000055fe135f3240 R08: 000055fe118be530 R09: 0000000000000001
[ 167.696186] R10: 0000000000000000 R11: 0000000000000246 R12: 0000000000000000
[ 167.696187] R13: 00007f6a85852000 R14: 0000000000000000 R15: 000055fe135f3240
[ 167.696188] Code: 4d 63 e6 e9 f2 fc ff ff 4c 89 45 d0 48 8b 47 10 e8 22 f0 9e 00 4c 8b 45 d0 e9 89 fc ff ff 4c 89 e7 e8 81 3f fd ff e9 aa fc ff ff <0f> 0b 49 c7 c4 f4 ff ff ff e9 c1 fc ff ff 0f 1f 40 00 66 2e 0f
[ 167.696200] ---[ end trace 7573f6868ea8f069 ]---
The QEMU crash is the same as well. We can reproduce the problem!
Testing the test Kernel
After that good news, I installed the test kernel which I built to the lab machine.
After rebooting and recompiling the kernel module we made, I started the script to create and destroy VMs and had a look at the reference counter:
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x1 or 1
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x1 or 1
$ cat /proc/zero_page_refcount
Zero Page Refcount: 0x1 or 1
Interesting. The fix seems to keep the reference counter glued to 1. It never changes, so it will never overflow. Looks good, it seems that the identified fix really does fix the problem. That’s reassuring.
Landing the Fix in the Kernel
As with all kernel bugs, we need to follow the Stable Release Updates procedure, and follow the special kernel specific rules.
This involves opening a launchpad bug and filling out a SRU template:
From there, I determined that the fixes needed to be landed in the 4.15 and 5.4 Ubuntu kernels, and I prepared patches to be submitted to the Ubuntu Kernel Mailing list:
After that, the patches get reviewed by senior members of the kernel team, and require 2 acks from them before it is accepted into the next SRU cycle:
From there, the patches were applied to the 4.15 and 5.4 kernel git trees:
From there we can check what kernel versions this will be included in:
For the 4.15 kernel:
$ git log --grep "KVM: fix overflow of zero page refcount with ksm running"
commit 4047f81f064d45f9f7e1ae9cac9a000f37af714c
Author: Zhuang Yanying <[email protected]>
Date: Mon Aug 17 11:51:54 2020 +1200
KVM: fix overflow of zero page refcount with ksm running
$ git describe --contains 4047f81f064d45f9f7e1ae9cac9a000f37af714c
Ubuntu-4.15.0-116.117~13
and the 5.4 kernel:
$ git log --grep "KVM: fix overflow of zero page refcount with ksm running"
commit 62f890e92628903a4fa2febd854edd12a0cea63a
Author: Zhuang Yanying <[email protected]>
Date: Mon Aug 17 11:51:54 2020 +1200
KVM: fix overflow of zero page refcount with ksm running
$ git describe --contains 62f890e92628903a4fa2febd854edd12a0cea63a
Ubuntu-5.4.0-46.50~509
We are tagged in the 4.15.0-116-generic and 5.4.0-46-generic kernels. These should be released to -updates within a few weeks of this blog post, then everyone can get this problem fixed.
Conclusion
That is how it’s done. We looked into a failure on an OpenStack compute node which paused all of its virtual machines, and we debugged the problem down to the kernel’s zero_page reference counter overflowing them Kernel Samepage Mapping is enabled.
We did some detective work, and managed to reproduce the problem without having to wait months for it to trigger, and managed to learn about writing a kernel module to help with our debugging. Finally, we got the fix landed in the Ubuntu kernels.
I hope you enjoyed the read, and as always, feel free to contact me.
Matthew Ruffell