As mentioned previously, I will write about particularly interesting cases I have worked from start to completion from time to time on this blog.
This is another of those cases. Today, we are going to look at a case where creating a seemingly innocent RAID array triggers a kernel bug which causes the system to allocate all of its memory and subsequently crash.
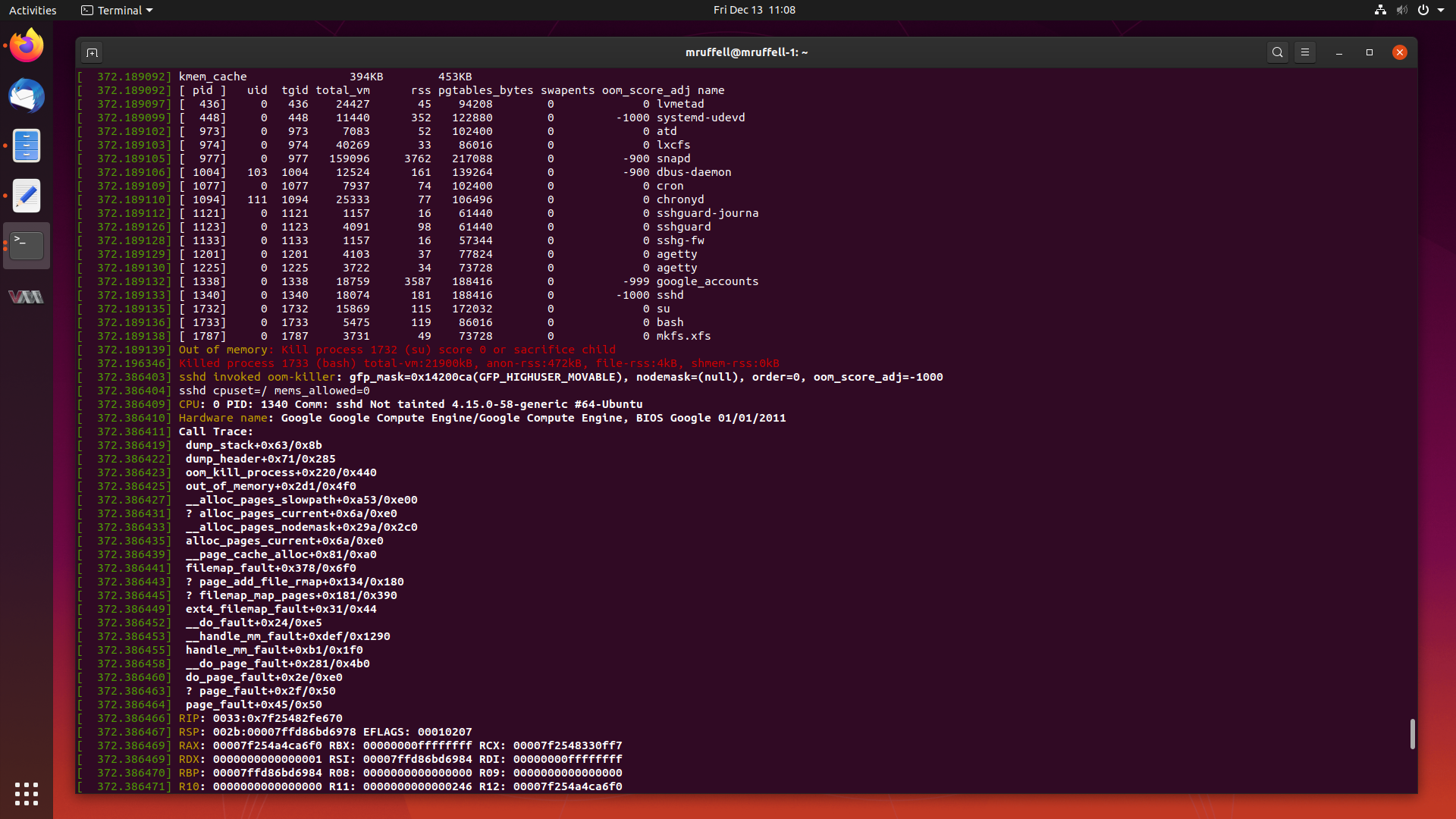
Let’s start digging into this and get this fixed.
Reproducing the Issue
Before we start hunting for kernel commits to see if we can fix the problem, it is always a good idea to reproduce the issue if possible and see what we can learn. This gives us a fresh set of logs on small isolated test systems, so we can be sure the command we previously ran caused the issue and not something else that may be running on a customer system.
Reading the case, the complaint is that when trying to format a RAID array of several disks with the xfs file system, the system hangs for a short time, ssh sessions disconnect, and if you reconnect, dmesg shows that the Out Of Memory (OOM) reaper has come out and killed most processes, including the SSH daemon.
The case mentions that the underlying disks are NVMe devices, so we will try and reproduce using NVMe disks.
Again, my system does not have any NVMe devices, let alone 8 of them, so we will probably use a cloud computing service for a test system. Google Cloud Platform is probably the best for this case, since it lets you easily add any number of NVMe based scratch disks to your instance.
Open up the dashboard, and create a new instance. Select Ubuntu 18.04 as the operating system, and leave the main disk as 10gb. Head down to the “Add additional disks” section, and from the dropdown, select “Local SSD Scratch disk” and make sure they are NVMe. In the number of disks, drag the slider to 8.
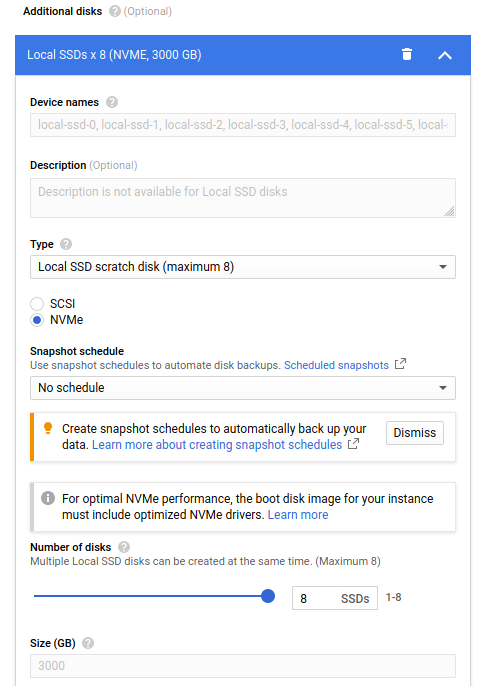
Go ahead and make the instance. It might be a little pricey, but we aren’t going to be using this instance for too long, so make sure to terminate it as soon as you are finished with it.
SSH into the instance. To reproduce, we need to be running the 4.15.0-58-generic kernel, so we can install that like so:
sudo apt updatesudo apt install linux-image-4.15.0-58-generic linux-modules-4.15.0-58-generic linux-modules-extra-4.15.0-58-generic linux-headers-4.15.0-58 linux-headers-4.15.0-58-genericsudo nano /etc/default/grub- Change
GRUB_DEFAULT=0toGRUB_DEFAULT="1>2"
- Change
sudo nano /etc/default/grub.d/50-cloudimg-settings.cfg- Comment out
GRUB_DEFAULT=0with a#.
- Comment out
sudo update-grubsudo reboot
This installs the 4.15.0-58 kernel and changes the grub config to boot into it by default, since we can’t open the grub menu on cloud instances.
Once the instance comes back up again, check uname -rv to ensure we are in
the correct kernel:
$ uname -rv
4.15.0-58-generic #64-Ubuntu SMP Tue Aug 6 11:12:41 UTC 2019
Good. Lets see what devices our NVMe disks are:
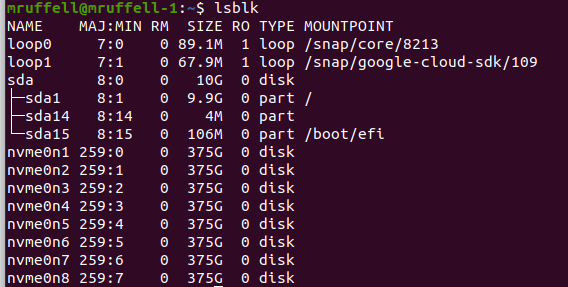
Seem to be based on nvme0nX.
Time to reproduce. Create a RAID array with:
sudo sumdadm --create /dev/md0 --level=0 --raid-devices=8 /dev/nvme0n1 /dev/nvme0n2 /dev/nvme0n3 /dev/nvme0n4 /dev/nvme0n5 /dev/nvme0n6 /dev/nvme0n7 /dev/nvme0n8mkfs.xfs -f /dev/md0
Nothing will happen for a few seconds, and then the SSH session will disconnect:
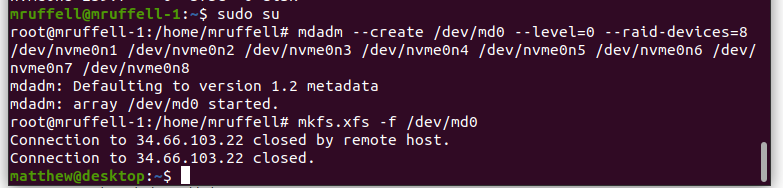
Pretty strange behaviour really. Reconnect, and examine dmesg:
CPU: 0 PID: 776 Comm: systemd-network Not tainted 4.15.0-58-generic #64-Ubuntu
Hardware name: Google Google Compute Engine/Google Compute Engine, BIOS Google 01/01/2011
Call Trace:
dump_stack+0x63/0x8b
dump_header+0x71/0x285
oom_kill_process+0x220/0x440
out_of_memory+0x2d1/0x4f0
__alloc_pages_slowpath+0xa53/0xe00
? alloc_pages_current+0x6a/0xe0
__alloc_pages_nodemask+0x29a/0x2c0
alloc_pages_current+0x6a/0xe0
__page_cache_alloc+0x81/0xa0
filemap_fault+0x378/0x6f0
? filemap_map_pages+0x181/0x390
ext4_filemap_fault+0x31/0x44
__do_fault+0x24/0xe5
__handle_mm_fault+0xdef/0x1290
handle_mm_fault+0xb1/0x1f0
__do_page_fault+0x281/0x4b0
do_page_fault+0x2e/0xe0
? page_fault+0x2f/0x50
page_fault+0x45/0x50
We see a fairly standard call trace saying the system hit a page fault, and when
it tried to allocate a new page with __page_cache_alloc(), that failed to,
taking the slowpath, which realised the system was out of memory, and invoked the
OOM reaper.
Reading down, we find a printout of all the memory currently located in the SLAB.
Unreclaimable slab info:
Name Used Total
RAWv6 15KB 15KB
UDPv6 15KB 15KB
TCPv6 31KB 31KB
mqueue_inode_cache 7KB 7KB
fuse_request 3KB 3KB
RAW 7KB 7KB
tw_sock_TCP 3KB 3KB
request_sock_TCP 3KB 3KB
TCP 16KB 16KB
hugetlbfs_inode_cache 7KB 7KB
eventpoll_pwq 7KB 7KB
eventpoll_epi 8KB 8KB
request_queue 118KB 311KB
dmaengine-unmap-256 30KB 30KB
dmaengine-unmap-128 15KB 15KB
file_lock_cache 3KB 3KB
net_namespace 27KB 27KB
shmem_inode_cache 476KB 550KB
taskstats 7KB 7KB
sigqueue 3KB 3KB
kernfs_node_cache 6726KB 6968KB
mnt_cache 146KB 146KB
filp 92KB 152KB
lsm_file_cache 35KB 35KB
nsproxy 3KB 3KB
vm_area_struct 74KB 108KB
mm_struct 61KB 61KB
files_cache 22KB 22KB
signal_cache 88KB 88KB
sighand_cache 185KB 185KB
task_struct 517KB 540KB
cred_jar 47KB 47KB
anon_vma 106KB 106KB
pid 114KB 140KB
Acpi-Operand 74KB 74KB
Acpi-ParseExt 7KB 7KB
Acpi-State 11KB 11KB
Acpi-Namespace 15KB 15KB
numa_policy 3KB 3KB
trace_event_file 122KB 122KB
ftrace_event_field 167KB 167KB
task_group 39KB 39KB
kmalloc-8192 1344KB 1344KB
kmalloc-4096 856KB 960KB
kmalloc-2048 1346KB 1424KB
kmalloc-1024 1042KB 1064KB
kmalloc-512 466KB 480KB
kmalloc-256 3499256KB 3499256KB
kmalloc-192 311KB 311KB
kmalloc-128 1156KB 1156KB
kmalloc-96 155KB 216KB
kmalloc-64 367KB 432KB
kmalloc-32 336KB 336KB
kmalloc-16 60KB 60KB
kmalloc-8 32KB 32KB
kmem_cache_node 80KB 80KB
kmem_cache 396KB 453KB
Everything looks pretty normal, apart from the kmalloc-256 slab. If you are
unfamiliar with how kernel memory allocation works in Linux, maybe take a moment
and read the blog post I wrote it on it here:
Looking at kmalloc() and the SLUB Memory Allocator
Back to the kmalloc-256 slab. Looking at it, there is 3499256KB used!
Converting 3499256KB to gigabytes gives us 3.49GB. Our little cloud instance
only has 3.75GB of ram by default, so it seems something has caused all the
system memory to get caught up in the kmalloc-256 slab.
Finding a Workaround
The next thing to do is try some other kernels to see if we can reproduce.
I tried the Bionic HWE kernel, based on the 5.0 kernel that Ubuntu 19.04 Disco Dingo uses. I wasn’t able to reproduce.
The next thing I tried was a previous Bionic kernel. The previous released kernel is 4.15.0-55-generic, and I wasn’t able to reproduce either.
Both are good news. Anyone affected by this bug can use the previous kernel or the HWE kernel while this gets fixed. It also tells us that this was introduced somewhere between 4.15.0-56 to 4.15.0-58.
Searching for the Root Cause
Time to dive into the commits for the kernel to see if we can determine anything from a quick look.
We know the problem between 4.15.0-56 to 4.15.0-58, so let’s have a look at those releases.
If we look at the git tree located at:
git://kernel.ubuntu.com/ubuntu/ubuntu-bionic.git
There are four tags we are interested in:
$ git tag
...
Ubuntu-4.15.0-55.60
Ubuntu-4.15.0-56.62
Ubuntu-4.15.0-57.63
Ubuntu-4.15.0-58.64
...
We can use git log to see what is in each tag:
git log --oneline Ubuntu-4.15.0-57.63..Ubuntu-4.15.0-58.64
9bff5f095923 (tag: Ubuntu-4.15.0-58.64) UBUNTU: Ubuntu-4.15.0-58.64
fca95d49540c Revert "new primitive: discard_new_inode()"
90c14a74ff26 Revert "ovl: set I_CREATING on inode being created"
544300b72249 UBUNTU: Start new release
Seems some small regressions were reverted in 4.15.0-58, and is otherwise a small release likely made late in the SRU cycle.
$ git log --oneline Ubuntu-4.15.0-56.62..Ubuntu-4.15.0-57.63
7c905029d1e1 (tag: Ubuntu-4.15.0-57.63) UBUNTU: Ubuntu-4.15.0-57.63
3536b6c0146c x86/speculation/swapgs: Exclude ATOMs from speculation through SWAPGS
fb8801640c8d x86/entry/64: Use JMP instead of JMPQ
1592edcea558 x86/speculation: Enable Spectre v1 swapgs mitigations
2efd2444a88e x86/speculation: Prepare entry code for Spectre v1 swapgs mitigations
cdb3893f2b04 x86/cpufeatures: Combine word 11 and 12 into a new scattered features word
a015c7c9e9f7 x86/cpufeatures: Carve out CQM features retrieval
ebd969e74a54 UBUNTU: update dkms package versions
29331dc18182 UBUNTU: Start new release
4.15.0-57 seems pretty quiet as well. Seems to be fixes for CVE-2019-1125, also not unusual to happen late in a SRU cycle.
The flaw is likely to fall into 4.15.0-56 then:
$ git log --oneline Ubuntu-4.15.0-55.60..Ubuntu-4.15.0-56.62 | wc -l
2787
2787 commits are present in 4.15.0-56! That is one big release, and we aren’t going to be able to read all of those commits.
I had a good read through all the subjects, and examined many commits, but nothing immediately jumped out as something that can cause the kernel to runaway, allocating memory until it cannot anymore, that is caused by the block, or filesystem, or maybe NVMe subsystems.
Since we are limited on time, and we know a definitive start and end points to
where the behaviour is introduced, and can easily reproduce the issue ourselves,
this case is a good candidate for a git bisect.
git bisect is a tool which uses a basic binary search algorithm to hone in on
a commit which breaks things. At each iteration, the midway point is selected
between good and bad commits. This lets us get through all 2787 commits in as
little as 12 or so tests.
We need to tell git bisect what tag is good and what tag is bad. We can do that like so:
$ git bisect start Ubuntu-4.15.0-56.62 Ubuntu-4.15.0-55.60
Bisecting: 1393 revisions left to test after this (roughly 11 steps)
[9cac6a2d2438924773cef5b30eab8f72d5a5ea3f] selftests/x86: Add clock_gettime() tests to test_vdso
We will look between 4.15.0-55, which was good, and 4.15.0-56, which was bad.
From here, we can go and build a test kernel, create a new cloud instance with lots of NVMe disks and try and reproduce. After doing all this, I can say that commit 9cac6a2d2438924773cef5b30eab8f72d5a5ea3f, which is halfway between 4.15.0-55 and 4.15.0-56, is good, and the problem could not be reproduced.
So I tell git that.
$ git bisect good
Bisecting: 696 revisions left to test after this (roughly 10 steps)
[621db8f68ea5dc1389cc29de188c62b708520115] vhost/scsi: truncate T10 PI iov_iter to prot_bytes
It gives us a new commit to test. This is halfway between 4.15.0-55 and 621db8f68ea5dc1389cc29de188c62b708520115, or on a bigger scale, a quarter of the way between 4.15.0-55 and 4.15.0-56. Nice. Again, build a test kernel, upload to a new cloud instance and try reproduce. This time, I managed to see the OOM problem, and the system crashed.
So I tell git that.
This keeps going until we hone in on the commit which causes the problem:
$ git bisect bad
Bisecting: 348 revisions left to test after this (roughly 9 steps)
[caed9931cfca4728ede493925804551759a17412] cdc-acm: fix race between reset and control messaging
$ git bisect good
Bisecting: 174 revisions left to test after this (roughly 8 steps)
[309d43a67a3a24ebf5ef72f3dcdc00dfcdd8c3fb] KVM: arm64: Fix caching of host MDCR_EL2 value
$ git bisect good
Bisecting: 87 revisions left to test after this (roughly 7 steps)
[d06521337ebd71f654b606612714c48e34aacd35] bcache: Populate writeback_rate_minimum attribute
$ git bisect bad
Bisecting: 43 revisions left to test after this (roughly 6 steps)
[97f76c511e9a41bc19282a921e53545ce08e168c] btrfs: Ensure btrfs_trim_fs can trim the whole filesystem
$ git bisect good
Bisecting: 21 revisions left to test after this (roughly 5 steps)
[edf57bb077f89c6e95003bdacc9478f52a37fd46] MD: fix invalid stored role for a disk - try2
$ git bisect good
Bisecting: 10 revisions left to test after this (roughly 4 steps)
[b6b0136869f05706228bb13511db7798af2c232b] mailbox: PCC: handle parse error
$ git bisect bad
Bisecting: 5 revisions left to test after this (roughly 3 steps)
[b515257f186e532e0668f7deabcb04b5d27505cf] block: make sure discard bio is aligned with logical block size
$ git bisect bad
Bisecting: 2 revisions left to test after this (roughly 1 step)
[da64877868c5ea90f741a31261205dae67139f59] mtd: spi-nor: fsl-quadspi: Don't let -EINVAL on the bus
$ git bisect good
Bisecting: 0 revisions left to test after this (roughly 1 step)
[3c2f83d8bcbedeb89efcaf55ae64a99dce9d7e34] block: don't deal with discard limit in blkdev_issue_discard()
$ git bisect bad
Bisecting: 0 revisions left to test after this (roughly 0 steps)
[894c8a9ad1d7e551bfbce5422c68816bc69146a2] bcache: correct dirty data statistics
$ git bisect good
3c2f83d8bcbedeb89efcaf55ae64a99dce9d7e34 is the first bad commit
commit 3c2f83d8bcbedeb89efcaf55ae64a99dce9d7e34
Author: Ming Lei <[email protected]>
Date: Fri Oct 12 15:53:10 2018 +0800
block: don't deal with discard limit in blkdev_issue_discard()
BugLink: https://bugs.launchpad.net/bugs/1836802
commit 744889b7cbb56a64f957e65ade7cb65fe3f35714 upstream.
blk_queue_split() does respect this limit via bio splitting, so no
need to do that in blkdev_issue_discard(), then we can align to
normal bio submit(bio_add_page() & submit_bio()).
More importantly, this patch fixes one issue introduced in a22c4d7e34402cc
("block: re-add discard_granularity and alignment checks"), in which
zero discard bio may be generated in case of zero alignment.
Fixes: a22c4d7e34402ccdf3 ("block: re-add discard_granularity and alignment checks")
:040000 040000 7483c1408acdee78933db770716b9b18f16d7644 b59d8fa70f2b07fb0a08b42aaab78daa8af57501 M block
Root Cause Analysis
The problem is caused by the below two commits:
commit: 744889b7cbb56a64f957e65ade7cb65fe3f35714
ubuntu-bionic: 3c2f83d8bcbedeb89efcaf55ae64a99dce9d7e34
Author: Ming Lei <[email protected]>
Date: Fri Oct 12 15:53:10 2018 +0800
Subject: block: don't deal with discard limit in blkdev_issue_discard()
BugLink: https://bugs.launchpad.net/bugs/1836802
commit: 1adfc5e4136f5967d591c399aff95b3b035f16b7
ubuntu-bionic: b515257f186e532e0668f7deabcb04b5d27505cf
Author: Ming Lei <[email protected]>
Date: Mon Oct 29 20:57:17 2018 +0800
Subject: block: make sure discard bio is aligned with logical block size
BugLink: https://bugs.launchpad.net/bugs/1836802
You can read them by looking at the text files below:
- block: don’t deal with discard limit in blkdev_issue_discard()
- block: make sure discard bio is aligned with logical block size
Now, the fault was triggered in two stages. Firstly, in “block: don’t deal with
discard limit in blkdev_issue_discard()” a while loop was changed such that
there is a possibility of an infinite loop if __blkdev_issue_discard() is called
with nr_sects > 0 and req_sects somehow becomes 0:
int __blkdev_issue_discard(..., sector_t nr_sects, ...)
{
...
while (nr_sects) {
unsigned int req_sects = nr_sects;
sector_t end_sect;
end_sect = sector + req_sects;
...
nr_sects -= req_sects;
sector = end_sect;
...
}
if req_sects is 0, then end_sect is always equal to sector, and the most
important part, nr_sects is only decremented in one place, by req_sects,
which if 0, would lead to the infinite loop condition.
Now, since req_sects is initially equal to nr_sects, the loop would never be
entered in the first place if nr_sects is 0.
This is where the second commit, “block: make sure discard bio is aligned with logical block size” comes in.
This commit adds a line to the above loop, to allow req_sects to be set to a
new value:
int __blkdev_issue_discard(..., sector_t nr_sects, ...)
{
...
while (nr_sects) {
unsigned int req_sects = nr_sects;
sector_t end_sect;
req_sects = min(req_sects, bio_allowed_max_sectors(q));
end_sect = sector + req_sects;
...
nr_sects -= req_sects;
sector = end_sect;
...
}
We see that req_sects will now be the minimum of itself and
bio_allowed_max_sectors(q), a new function introduced by the same commit.
static inline unsigned int bio_allowed_max_sectors(struct request_queue *q)
{
return round_down(UINT_MAX, queue_logical_block_size(q)) >> 9;
}
queue_logical_block_size(q) queries the hardware for the logical block size of
the underlying device.
static inline unsigned short queue_logical_block_size(struct request_queue *q)
{
int retval = 512;
if (q && q->limits.logical_block_size)
retval = q->limits.logical_block_size;
return retval;
}
If q->limits.logical_block_size is 512 or smaller, then bit shifted right by 9
yields 0.
bio_allowed_max_sectors() will return 0, and the min with req_sects == nr_sects
will favour the new 0.
This causes nr_sects to never be decremented since req_sects is 0, and
req_sects will never change since the min() that takes in itself will always
favour the 0.
From there the infinite loop iterates and fills up the kmalloc-256 slab with
newly created bio entries, until all memory is exhausted and the OOM reaper
comes out and starts killing processes, which is ineffective since this is a
kernel memory leak.
Finding the Commit With the Fix
The fix comes in the form of:
commit: b88aef36b87c9787a4db724923ec4f57dfd513f3
ubuntu-bionic: a55264933f12c2fdc28a66841c4724021e8c1caf
Author: Mikulas Patocka <[email protected]>
Date: Tue Jul 3 13:34:22 2018 -0400
Subject: block: fix infinite loop if the device loses discard capability
BugLink: https://bugs.launchpad.net/bugs/1837257
You can read it here:
This adds a check right after the min(req_sects, bio_allowed_max_sectors(q));
to test if req_sects has been set to 0, and if it has, to exit the loop and
move into failure handling:
...
req_sects = min(req_sects, bio_allowed_max_sectors(q));
if (!req_sects)
goto fail;
...
From there things work as normal. As “block: fix infinite loop if the device
loses discard capability” points out, all of this is triggered due to a race
where if underlying device is reloaded with a metadata table that doesn’t
support the discard operation, then q->limits.max_discard_sectors is set to 0
and has a knock on effect of setting q->limits.logical_block_size to strange
values and leads to the infinite loop and out of memory condition.
Landing the Fix in the Kernel
As with all kernel bugs, we need to follow the Stable Release Updates procedure, and follow the special kernel specific rules.
This involves opening a launchpad bug and filling out a SRU template:
For this particular SRU I got lucky, since “block: fix infinite loop if the device loses discard capability” was already pulled in from a upstream -stable release and already applied to master-next via:
So I did not need to submit any patches to the Ubuntu kernel mailing list. Poor me haha. Don’t worry, there’s always next time.
The commit made its way into 4.15.0-59-generic and was eventually released as 4.15.0-60-generic. If you are using this kernel or newer, you will be running a fixed kernel and you will not see this issue.
Conclusion
There you have it. We reproduced and determined the root cause of a runaway kernel memory allocation that consumed the entire system memory, and made sure it got fixed in the next kernel update.
This case was an excellent example of when to use git bisect, since we had
everything required for it to be an effective tool for this situation.
We had a close analysis of the code and managed to determine exactly what caused
the infinite loop to occur, and how the fix holds up. I’m pretty happy with how
this got resolved, even if git bisect is a little bland compared to other more
exotic bug finding tools.
I hope you enjoyed the read, and as always, feel free to contact me.
Matthew Ruffell